
Data science job opportunities look larger than many job seekers realize, but the headline number only tells part of the story. Employment of data scientists is projected to grow 34% from 2024 to 2034, and the U.S. Bureau of Labor Statistics also projects about 23,400 openings each year over that period, which signals both expansion and replacement hiring in a market that still rewards specialization and proof of impact (U.S. Bureau of Labor Statistics data scientist outlook).
The practical issue is that candidates often chase one title, while employers often write one job description that combines three jobs. That mismatch slows hiring, creates weak shortlists, and causes strong people to miss solid roles that sit just outside the classic “data scientist” label.
The better approach is narrower and broader at the same time. Narrower in how skills are positioned. Broader in how roles are targeted. For readers tracking longer-term market direction, Nexus has also published a useful look at the future of data science careers and predictions.
Table of Contents
- The Booming Data Job Market in 2026
- A Spectrum of Roles The Modern Data Team
- In-Demand Skills Beyond the Buzzwords
- Top Industries and Employers Hiring Data Talent
- A Candidate’s Playbook for Landing the Right Role
- An Employer’s Guide to Winning the War for Talent
- Salary Benchmarks and the Remote Work Landscape
The Booming Data Job Market in 2026
Data hiring remains strong in 2026, but the easier opportunities are gone. Candidates are no longer competing on interest, certificates, or a long tools list. They are competing on fit, business judgment, and evidence that they can solve a specific problem.
That shift matters for both sides of the market.
Candidates who search only for “data scientist” miss a large share of the overall opportunity. Many of the strongest openings sit in analytics-heavy roles tied to revenue, product, operations, finance, and experimentation. Employers feel the same mismatch from the other direction. They open a search for a model-builder, then realize the team needs someone who can define metrics, clean up reporting logic, support decisions, and work with stakeholders who do not speak in technical shorthand.
Demand is real, but the market rewards clarity
The broad demand signal is still positive, as noted earlier. What has changed is how employers evaluate value. Hiring teams are more willing to pay for applied impact than for broad technical potential, especially in mid-market companies and enterprise teams under budget pressure.
I see this pattern often in searches tied to business performance. A hiring manager asks for Python, machine learning, and advanced statistics. After intake, the actual success profile turns out to be SQL depth, experimentation support, KPI ownership, and the ability to explain why one metric should drive a decision over another. Those are data science jobs in practice, even if the title says analyst, analytics engineer, or product analytics lead.
For candidates, the takeaway is simple. Market yourself around outcomes and scope, not just tools. For employers, write the job around decisions, ownership, and business context, then add the technical stack.
Practical rule: The market pays for people who can solve a defined business problem with the right mix of analysis, engineering, communication, and judgment.
The 2026 hiring market also punishes vague positioning. A resume packed with technologies but thin on results usually stalls. A job description packed with buzzwords but vague on ownership usually brings the wrong applicants, slower shortlists, and more interview waste.
Two audiences, one hiring reality
Candidates want progression, stronger pay, and work that builds long-term market value. Employers want people who can ramp quickly and operate with limited supervision. Those goals match up well when the role is defined properly.
The strongest candidates in this market are not always the most academic. They are often the ones who can connect analysis to a commercial outcome, explain trade-offs, and work comfortably in roles that sit closer to reporting, experimentation, forecasting, pricing, or decision support than pure model research. That is also why data science career paths and hiring trends for the next decade matter beyond title inflation. The best career moves often come from choosing a role with clear business ownership, not the flashiest label.
For hiring managers, the message is just as direct. Teams that know whether they need a data scientist, BI lead, analytics engineer, or machine learning engineer fill faster and close stronger candidates more often.
Most of the opportunity sits in role definition, targeted skill matching, and realistic expectations on both sides.
A Spectrum of Roles The Modern Data Team
Hiring data talent goes sideways when every opening gets labeled “data scientist.” In practice, modern teams split the work across roles with different output, tooling, and business exposure. The candidate who would struggle in a research-heavy modeling seat may be excellent in product analytics, pricing, BI, or analytics engineering. Employers miss good hires when they collapse those jobs into one title. Candidates miss strong career paths when they search too narrowly.
The strongest long-term opportunities often sit in analytics-heavy roles that are closer to revenue, operations, customer behavior, and executive decision support. Those jobs may involve less model building and more metric design, experimentation, forecasting, dashboard logic, or stakeholder management. They are still data careers. In many teams, they are also the roles with clearer ownership and faster business impact.
A good data team usually includes several role families, not one catch-all hire.
Why title matching fails
Title inflation creates noise on both sides of the market. I see “Data Scientist” used for SQL-heavy analytics jobs, dashboard ownership roles, and even reporting positions with little statistical work. I also see candidates rule out “BI Developer” or “Analytics Engineer” jobs that would give them better mentorship, more visibility with leadership, and stronger promotion paths.
Job titles help with search. Scope determines fit.
A posting called “Data Scientist” may really be a product analytics role with heavy stakeholder communication and A/B test analysis. An “Analytics Engineer” role may suit someone who likes defining trusted metrics, cleaning business logic, and building models in the warehouse that finance, product, and operations can use every day. A “BI Developer” job may offer more influence on business decisions than an entry-level modeling role, especially in companies that run on reporting cadence and KPI reviews.
Candidates who understand that distinction tend to interview better because they can explain what work they want to own, not just what title they want to hold. Hiring managers benefit too. Clear role design cuts wasted interviews and improves close rates.
Data Role Cheat Sheet
| Role | Core Function | Key Skills | Primary Business Goal |
|---|---|---|---|
| Data Analyst | Interprets data, builds reports, answers business questions | SQL, Excel, Tableau, Power BI, stakeholder communication | Improve decisions with clear insights |
| Data Scientist | Builds analytical models and investigates patterns | Python or R, statistics, experimentation, feature analysis | Support forecasting, optimization, and deeper analysis |
| Data Engineer | Builds and maintains pipelines and data infrastructure | SQL, Python, Spark, dbt, Airflow, cloud platforms | Deliver reliable, usable data at scale |
| Machine Learning Engineer | Deploys and maintains production models | Python, MLOps, APIs, testing, cloud tooling | Turn models into working software |
| BI Developer | Designs dashboards, semantic layers, reporting logic | SQL, BI tools, metric design, visualization | Create trusted reporting for business users |
| Analytics Engineer | Transforms raw data into business-ready models | SQL, dbt, warehouse modeling, documentation | Improve data usability and consistency |
| Research Scientist | Explores advanced methods and novel modeling approaches | Statistics, ML, experimentation, domain depth | Solve harder analytical or quantitative problems |
Where the market gets more interesting
The overlooked middle of the market is where many employers are hiring and many candidates under-apply. That includes product analysts, decision scientists, marketing analysts, revenue analysts, experimentation specialists, BI leads, and analytics engineers. These roles usually sit closer to commercial outcomes than pure research work. They also build habits that travel well across industries: metric judgment, business framing, data quality discipline, and communication with non-technical leaders.
For candidates, that means a career path does not need to start with machine learning to become valuable. A strong analyst who owns forecasting, pricing analysis, experiment readouts, or executive reporting can build a very durable profile. For employers, it means the hiring brief should start with the business problem. If the team needs cleaner inputs, stable reporting, and better KPI definitions, hiring a generalist “data scientist” often creates mismatch. If the team needs models shipped into production systems, the better hire may be an ML engineer or a software-leaning applied scientist.
How employers should read these distinctions
Start with the work product. Then choose the title.
If success means trusted dashboards, cleaner definitions, and fewer reporting disputes, hire for analytics engineering or BI. If success means better experiment design, customer segmentation, or pricing analysis, hire for product analytics or decision science. If success means production inference, retraining pipelines, and model monitoring, hire for machine learning engineering.
That sounds obvious, but many teams still write one broad job description and hope interviews sort it out. They rarely do. Strong candidates can spot fuzzy ownership quickly, and niche candidates usually leave the process first.
For candidates, precision signals maturity. “I build stakeholder-facing analytics systems and define metrics teams can run the business on” is far stronger than “I am passionate about AI and data.” The first tells a recruiter where you fit. The second tells us very little.
In-Demand Skills Beyond the Buzzwords
A lot of candidates still assume advanced machine learning is the main path to strong data science job opportunities. In the current market, that assumption causes unnecessary competition. Many employers aren’t hiring for novelty. They’re hiring for clarity, reliability, and decision support.
Recent industry commentary has highlighted a point recruiters see every day. Many higher-paying data roles don’t require machine learning at all. Employers pay for advanced SQL, data storytelling, quality testing, documentation, and decision support, and some senior analyst and analytics leadership roles reach roughly $150k to $250k in some markets (discussion of higher-paying analytics-focused roles).
What employers actually screen for
The first screen is rarely as glamorous as candidates expect. Employers want to know whether someone can work with messy data, define a metric correctly, spot a flawed assumption, and explain conclusions without hiding behind jargon.
The practical skill stack often looks like this:
- Advanced SQL: Complex joins, window functions, CTEs, cohort logic, and performance awareness still matter because so much business analysis starts in the warehouse.
- Data storytelling: Teams need people who can explain what changed, why it matters, what confidence exists in the conclusion, and what action should follow.
- Testing and quality discipline: Clean dashboards, validated pipelines, and documented assumptions earn trust faster than clever notebooks nobody can operationalize.
- Decision support: The most valuable analysts don’t just report movement. They frame choices and trade-offs for product, finance, operations, and executive stakeholders.
- Communication with non-technical teams: Strong candidates can adjust their explanation for a VP, product manager, or operations lead without sounding watered down.
How candidates should build a T-shaped profile
A T-shaped profile is still the most practical model. One area should be deep enough to make hiring managers confident. The horizontal bar should be broad enough to make collaboration easy.
A useful version looks like this:
- Choose one depth area. That might be experimentation, analytics engineering, forecasting, product analytics, causal inference, MLOps, or BI architecture.
- Build around business fluency. Learn how revenue, retention, margin, fraud, risk, or operational throughput is measured in the target industry.
- Show work in business terms. A portfolio should explain the problem, the data constraints, the choices made, and the result the work enabled.
- Document like a professional. Good README files, metric definitions, assumptions, validation steps, and concise takeaways signal readiness for team environments.
A candidate who can write clean SQL, validate definitions, and brief an executive clearly is often harder to find than a candidate who can train another model.
What doesn’t work is piling up disconnected tools. A resume that lists Python, TensorFlow, Spark, Snowflake, Tableau, dbt, and Kubernetes without context usually reads as shallow. Employers don’t need a shopping list. They need evidence that the candidate can own a slice of real work.
Top Industries and Employers Hiring Data Talent
Data hiring stays broad even when headlines focus on AI research. In practice, the strongest hiring volume often sits in roles tied to revenue, retention, risk, operations, and reporting. That matters for candidates who want durable career paths, and for employers that keep writing narrow “unicorn” job specs for work that is mostly analytics and decision support.
Candidates who understand how value gets created in each sector target better. Employers who define the business problem first usually fill roles faster and make fewer expensive hiring mistakes.

Where the work differs by industry
In our experience placing candidates, technology companies often hire around product, growth, pricing, and customer behavior questions. They need people who can define clean metrics, support experiments, explain user patterns, and work well with product managers and engineering leads. SQL, metric judgment, and communication carry real weight here. Pure modeling skill rarely carries the process on its own.
Finance and quant hiring splits into very different markets. Banks, insurers, and corporate finance teams often need talent for risk, forecasting, controls, fraud, and regulatory reporting. Quant funds and highly systematic trading firms screen for narrower profiles such as research scientists, machine learning engineers, and developers who can work close to production models. Same broad field, very different interview bar.
Healthcare employers hire with more caution because the cost of bad data is higher. Reporting integrity, governance, patient or operational workflow knowledge, and stakeholder alignment often matter as much as technical range. This is one of the clearest examples of strong careers outside classic model-building. We regularly see analytics engineers, BI leads, and decision support professionals outperform more theoretical candidates because the work depends on trust, documentation, and adoption.
Consulting firms buy flexibility. They need data professionals who can switch industries, clean messy inputs, frame findings clearly, and present to client leadership without losing the thread. Breadth matters, but so does stamina. The pace can be good for candidates who like variety and rougher problem definition.
Startup demand versus enterprise demand
Startups usually hire for coverage. One person may need to write SQL, shape dashboards, define KPIs, sanity-check a model, and brief leadership in the same week. That can accelerate growth for candidates who like ambiguity and broad ownership. It also creates risk. Some startup “data scientist” roles are really first-analytics-hire jobs with weak infrastructure and unclear priorities.
Enterprises hire more narrowly. Scope is cleaner, tooling is often better, and stakeholder groups are easier to map. The trade-off is specialization. A candidate can become very good at one slice of reporting, experimentation, or pipeline support and then struggle to reposition later if the resume does not show business impact across functions.
That trade-off is where many searches go wrong.
Hiring managers should calibrate by operating environment, not title alone. A healthcare BI candidate should not face the same process as a recommender systems engineer. A quant researcher should not get a generic analyst case. Teams that want help structuring role-specific screens can use a practical data science interview preparation guide to tighten evaluation around the actual work.
The best target industry is the one that matches the problems a candidate can solve repeatedly, and the one where an employer can explain success in concrete business terms. That is especially true for analytics-heavy roles, which are often easier to hire for, easier to ramp, and closer to measurable business outcomes than employers first assume.
A Candidate’s Playbook for Landing the Right Role
Many data candidates lose good opportunities for reasons that have nothing to do with technical ability. The problem is positioning. They apply by title, send the same resume to every opening, and miss the roles where their background would carry weight.
The strongest searches are built around fit between business problems and proven strengths. That is especially true in analytics-heavy roles. Product analytics, BI, analytics engineering, decision science, and commercial strategy roles often have clearer hiring signals than broad “data scientist” postings, and they can offer faster path-to-impact for candidates who know how to show business value.
How to search smarter
Start with role families, not title preferences.
Candidates searching for data science job opportunities should cast a wider but more disciplined net across analytics engineer, product analyst, BI developer, decision scientist, machine learning engineer, quantitative researcher, and data engineer roles. The key test is transferable work, not keyword overlap. A candidate who has improved pricing, retention, forecasting, experimentation, or executive reporting may be a stronger fit for an analytics-heavy role than for a pure modeling job, even if the title sounds less prestigious on paper.
A practical search process usually includes four moves:
- Choose the operating environment carefully: Startup, enterprise, consulting, healthcare, fintech, and quant shops value the same skills differently. A candidate who thrives in messy, high-ownership environments may stall in a tightly scoped enterprise role, and the reverse is just as common.
- Tailor the portfolio to the work: Product analytics candidates should show experiment design, metric definition, funnel analysis, and recommendations that changed a roadmap or KPI. Analytics engineering candidates should show data modeling, transformation logic, testing, and trust in the underlying data.
- Use recruiters with a clear purpose: Specialist recruiters help most when the role is narrow, the market is thin, or the candidate needs help accessing employers that screen tightly for domain fit.
- Network around business problems: Strong outreach mentions the team, the problem, and the relevant result. “I saw your team is investing in self-serve analytics for operations” gets more traction than “I would love to connect.”
One pattern I see often: strong candidates aim too narrowly at model-building roles and ignore adjacent positions that are easier to win and often closer to revenue, retention, or operational performance. That is a mistake if the long-term goal is influence, not just technical purity.
What a strong process looks like
A good resume makes hiring managers do less work. It shows where the candidate operated, what problem they owned, how they approached it, and what decision changed because of the work.
Strong bullets usually cover four points:
- The business problem
- The data, system, or process involved
- The methods or tools used
- The outcome, recommendation, or decision supported
That format works well because it maps to how data leaders hire. They are not just asking, “Can this person code?” They are asking whether the candidate can improve a decision, reduce ambiguity, and communicate clearly with stakeholders who do not care about tool names.
Interview prep should follow the same logic. SQL screens test reasoning. Case rounds test prioritization and judgment. Hiring manager interviews test ownership, trade-off thinking, and communication under pressure. Candidates who want a tighter prep structure can review this guide on preparing for a data science interview.
Candidates stand out when they explain trade-offs clearly. Why this metric. Why this model. Why this level of complexity. Why this recommendation.
A few habits hurt otherwise strong applicants:
- Relying too much on coursework: Employers want evidence of execution in real or realistic settings.
- Using one resume for every data role: BI, analytics, data engineering, and machine learning searches often require different framing.
- Listing tools instead of decisions: Python, dbt, Tableau, and Spark matter. The business judgment behind the work matters more.
- Underselling analytics-heavy experience: Work tied to forecasting, experimentation, KPI design, segmentation, pricing, or executive reporting is often more commercially valuable than candidates realize.
A disciplined search can feel slower in week one. It usually produces better interviews, better offer alignment, and fewer title-driven mistakes.
An Employer’s Guide to Winning the War for Talent
Most hiring problems in data start before sourcing. The company hasn’t defined what success looks like, which team owns the work, or whether the hire needs to build, analyze, influence, or operationalize. Then the job description turns into a catch-all. The market responds with mismatched applicants.
Employers that hire well usually do three things early. They define the business problem, reduce unnecessary requirements, and build an interview process that respects the candidate’s time.
Fix the job before filling the job
A good intake meeting should answer a few hard questions.
- What business decision will this person improve? Revenue forecasting, retention, experimentation, fraud detection, executive reporting, platform reliability, and ML deployment are very different jobs.
- What is the first six-month mandate? A role with near-term dashboard cleanup needs a different profile than one expected to stand up feature pipelines.
- Which skills are required on day one? If Python can be learned on the job but stakeholder management can’t, the process should reflect that.
- Who consumes this person’s work? Product leaders, traders, finance heads, clinicians, or operations teams will each require a different communication style.
Many postings fail. They ask for every modern tool, advanced machine learning, deep statistics, flawless communication, and domain expertise in one person. That profile exists rarely, and when it does, the market knows it.
How to assess without driving candidates away
Data hiring should test real work, not endurance. Long processes with repetitive screens lose strong candidates, especially passive ones.
A better structure usually includes:
- A focused recruiter or screening call: Validate scope, communication, and alignment early.
- One practical technical assessment: SQL, logic, data interpretation, or architecture discussion depending on the role.
- A stakeholder interview: Someone should evaluate whether the candidate can explain ideas to the people who’ll rely on the work.
- A sensible take-home, if used: Keep it short, realistic, and relevant. If the work would take meaningful unpaid effort, expectations should be reduced or the format should change.
Hiring managers should stop treating every data role like an academic defense. Most teams need applied judgment, not a performance of theoretical completeness.
The best employers also know how to sell the role. Strong candidates care about manager quality, data maturity, decision access, and whether the company will act on the work. Compensation matters, but serious professionals also want a role with influence and credibility.
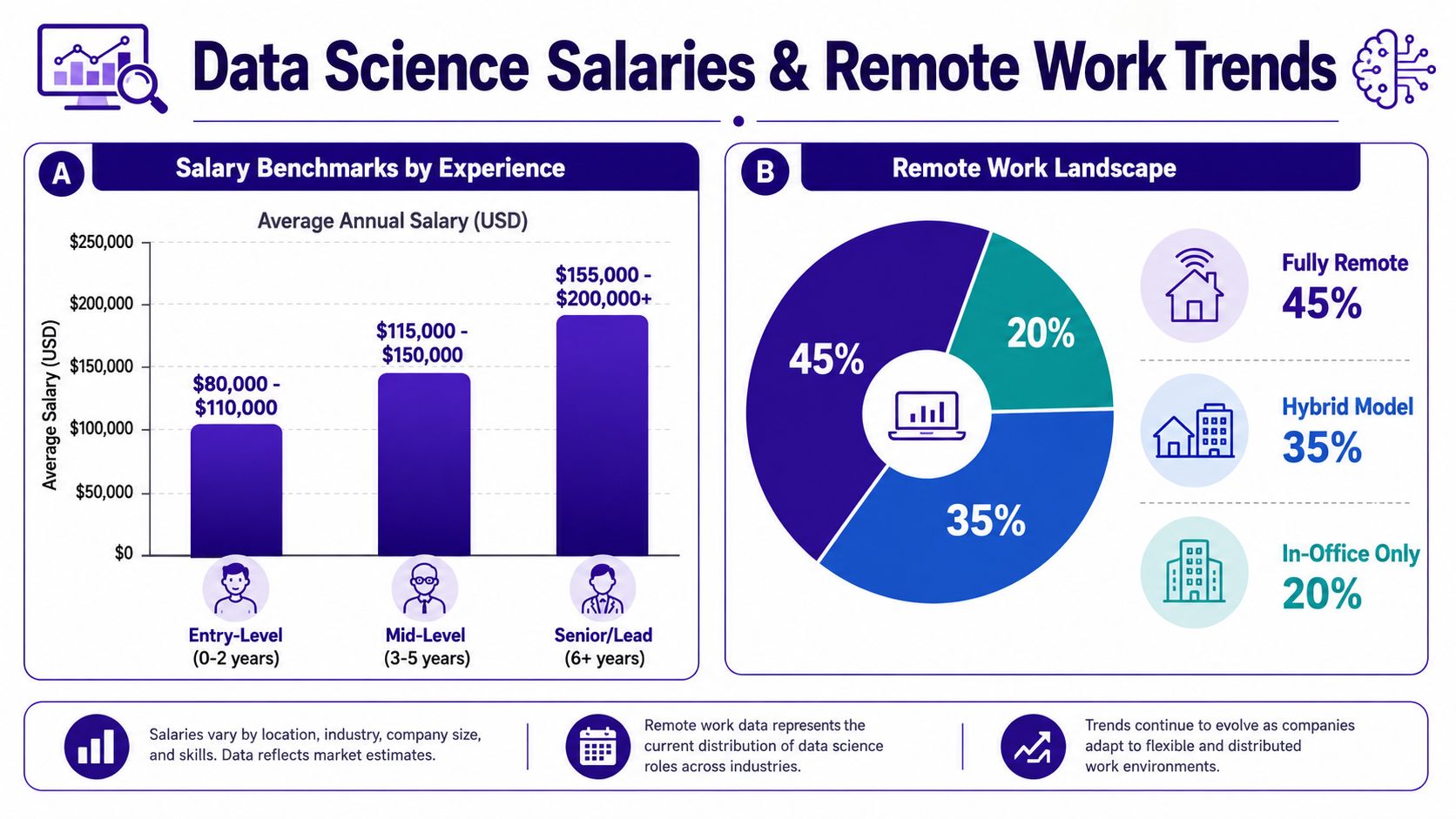
Salary Benchmarks and the Remote Work Landscape
Salary discussions in data hiring go wrong fast when different jobs get grouped under the same title. A machine learning scientist, a BI analyst, and an analytics engineering manager may all sit in the same talent pool, but the work, pressure, and business value are not priced the same way.
The better comparison is role scope. Candidates should assess compensation based on technical depth, ownership, stakeholder exposure, and how directly the work affects revenue, cost, or operational decisions. Employers should benchmark against the work performed, not the label on the posting.
That distinction matters even more in analytics-heavy roles. In many hiring processes, I see candidates overlook strong paths in BI, product analytics, decision science, and analytics engineering because they are chasing a narrower idea of “data science.” Employers make the same mistake when they underpay these seats, then wonder why hiring drags. Teams that turn messy data into decisions often create value faster than teams building models that never reach production.
What compensation signals really mean
Good salary benchmarking starts with more than one reference point. For analytics-focused positions, this BI Analyst salary guide for 2026 gives useful context on how pay shifts by seniority and market.
Base salary is only part of the offer. Strong candidates also look at bonus structure, equity, reporting line, team maturity, and whether the role owns a decision process or only supports one. A senior title with narrow influence usually loses against a slightly lower title with broader scope and better executive access.
For a broader role-by-role view, review this data science salary guide.
How remote work changes the hiring equation
Remote work widened the talent pool. It did not make every data job equally location-flexible.
Roles tied closely to executives, product leaders, regulated data, or fast feedback loops often work better in hybrid setups. Analytics engineering, BI, and some platform-focused positions can be easier to hire remotely if documentation is strong, ownership is clear, and decision-making does not depend on hallway conversations.
Candidates should ask blunt questions. Who attends planning meetings? Who presents findings to leadership? Do remote employees own high-visibility work, or do they become report builders for people in the office? Those answers tell you more than a remote label on a job post.
Hiring managers should be just as direct. If the job needs in-person stakeholder management twice a week, say so. If remote employees are evaluated by output and have equal access to leadership, say that too. Clear expectations close more offers than vague flexibility language.
As noted earlier, nexus IT group provides staffing and search support across data, analytics, machine learning, and quant hiring for both employers and candidates.