
A lot of developers land on Python’s random.uniform() while doing something routine: generating test inputs, mocking a sensor range, jittering timestamps, or filling a synthetic feature column with continuous values. The function looks simple enough that it rarely gets a second thought.
That simplicity is exactly why it causes trouble in production code. Most examples stop at syntax. They don’t deal with the two mistakes that break real systems: assuming the upper bound behaves like a hard mathematical guarantee, and treating a one-dimensional random float generator as if it automatically solves geometric sampling problems.
This guide stays practical. It focuses on how Python Random Uniform behaves in code, where it’s safe, where it isn’t, and what to do when a quick demo turns into test infrastructure, simulation logic, or data generation pipelines.
Table of Contents
- Why You Need Random Floats in Python
- Understanding Uniform Distribution
- Practical Syntax and Code Examples
- Ensuring Reproducibility with Seeding
- Common Pitfalls and Critical Edge Cases
- When to Use NumPy Instead of Random
Why You Need Random Floats in Python
A common use case starts with a bounded real-world value. A backend team may need mock temperature readings, a fraud model may need continuous feature values, or a game system may need slight movement variation that doesn’t snap to integers. In all of those cases, integer-based randomness is the wrong tool.
random.uniform(a, b) fits when the code needs a floating-point value somewhere within a range and there’s no intended bias toward one part of that interval. That makes it useful for simulation stubs, randomized test fixtures, and synthetic datasets where values should spread across a continuous band instead of clustering around a center.
One reason this matters in hiring and interview prep is that random data generation shows up in practical coding tasks more often than many people expect. Teams working toward quant, simulation, and modeling roles often run into this class of problem early, especially when moving from toy exercises into scenario generation. For readers exploring that path, this guide on becoming a quant gives useful career context around the kinds of technical environments where this work appears.
Where Python Random Uniform shows up
- Test data generation for APIs that accept decimal measurements, prices, probabilities, or coordinates.
- Simulation inputs where a value can fall anywhere in a bounded interval.
- Controlled noise injection for benchmarking and resilience testing.
- Synthetic features for machine learning experiments before real data pipelines are ready.
Practical rule: Use
random.uniform()when the problem is “pick one scalar float from a range.” The moment the problem becomes geometric, directional, or array-heavy, the design needs another look.
That distinction sounds minor. It isn’t. It determines whether the resulting data is merely random-looking or correct for the system being tested.
Understanding Uniform Distribution
Uniform doesn’t mean “random enough.” It means every value across the interval is treated evenly in the model. If the code asks for a float between two bounds, no subrange should get privileged treatment unless the developer intentionally chooses a different distribution.
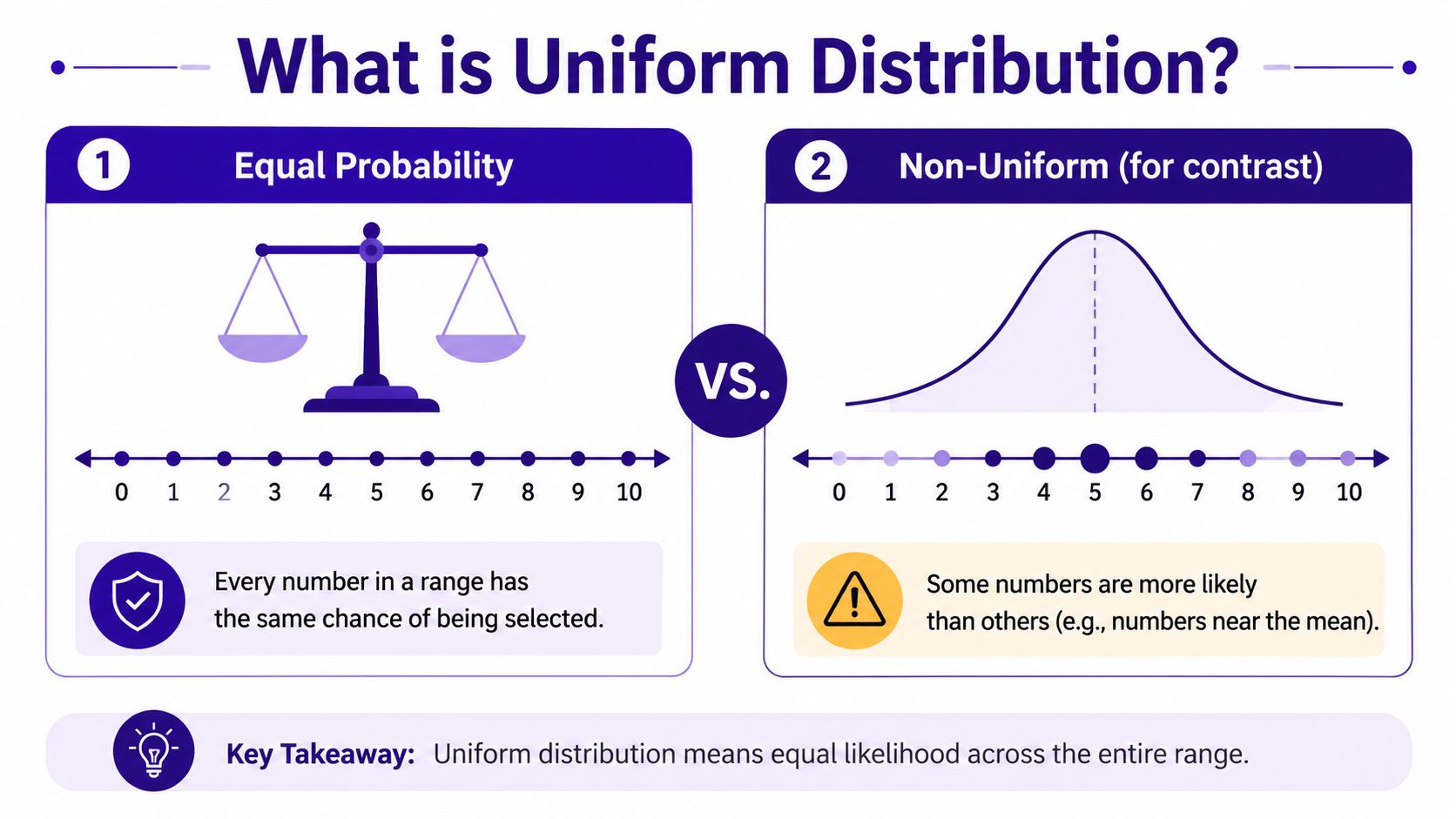
A useful mental model is an infinitely fine number line. Uniform sampling doesn’t favor the middle, the edges, or tidy decimal values. It spreads choices evenly across the interval. That makes it very different from a normal distribution, where values tend to cluster near a mean.
What uniform means in practice
When developers choose Python Random Uniform, they’re usually encoding one of these assumptions:
- No preferred zone exists within the range.
- Any valid float is acceptable as long as it falls between the bounds.
- The variable is scalar, not spatial or directional.
That last point matters more than it first appears. Uniformity in one dimension doesn’t automatically become uniformity in two dimensions. A value sampled uniformly from a radius is not the same thing as a point sampled uniformly from an area.
Uniform randomness is about the model, not just the function call. A correct-looking API call can still encode the wrong probability distribution for the problem.
Uniform vs. normal distribution
| Uniform vs. Normal Distribution | Uniform | Normal |
|---|---|---|
| Probability across range | Even across the interval | Concentrated around a center |
| Typical use | Bounds with no bias | Natural variation around an average |
| Visual shape | Flat | Bell-shaped |
| Common mistake | Assuming it solves geometry automatically | Using it when bounds matter more than central tendency |
Developers often pick uniform because it feels neutral. Sometimes that's exactly right. Sometimes it can inject the wrong structure into data. The safest approach is to tie the distribution to the meaning of the variable, not just the convenience of the API.
Practical Syntax and Code Examples
The standard library version lives in Python's built-in random module. In day-to-day code, the call is straightforward.

Basic usage
import random
value = random.uniform(10.5, 35.8)
print(value)
print(type(value)) # float
The return type is a float. That sounds obvious, but it matters when the generated value later feeds validation logic, serialization, or downstream calculations that assume decimal behavior.
Generating multiple values
For test fixtures or synthetic rows, a list comprehension is usually cleaner than repeatedly appending inside a loop.
import random
sensor_readings = [random.uniform(10.5, 35.8) for _ in range(5)]
print(sensor_readings)
That pattern works well for lightweight generation inside scripts, tests, and small utilities. It also makes the intended shape of the data obvious at a glance.
Using the result in application logic
Random floats become more useful when they sit inside structures the rest of the application already understands.
import random
payload = {
"temperature_c": random.uniform(10.5, 35.8),
"humidity": random.uniform(20.0, 80.0),
"pressure": random.uniform(980.0, 1030.0),
}
print(payload)
This is a practical pattern for API mocks, local integration testing, and event-stream prototypes.
Reversed bounds
Python's API is forgiving about argument order. If code passes a larger first value and a smaller second value, the function still produces a float between those endpoints.
import random
value = random.uniform(5.0, 1.0)
print(value)
That convenience cuts both ways. It helps in quick scripts, but it can also hide configuration mistakes. In production code, explicit validation is usually better than relying on permissive behavior.
A safer wrapper for application code
import random
def uniform_between(low: float, high: float) -> float:
if low > high:
raise ValueError(f"low must be <= high, got {low} > {high}")
return random.uniform(low, high)
print(uniform_between(1.0, 5.0))
Best practice: If a reversed range indicates bad input in the business domain, fail fast instead of silently accepting it.
That small wrapper prevents bad config values from leaking into data generation and makes failures easier to diagnose.
Ensuring Reproducibility with Seeding
Random values are useful in tests until they make failures impossible to reproduce. A flaky test that only breaks on one run out of many is harder to debug than a consistently failing test. That's where seeding becomes part of basic engineering hygiene.
Python's random module generates pseudo-random values. The sequence comes from a deterministic algorithm. When code sets the seed explicitly, it can replay the same sequence on demand.
Seeded versus unseeded behavior
Without a seed, repeated runs produce different sequences.
import random
print(random.uniform(0.0, 1.0))
print(random.uniform(0.0, 1.0))
print(random.uniform(0.0, 1.0))
With a seed, the sequence becomes repeatable for debugging and tests.
import random
random.seed(42)
print(random.uniform(0.0, 1.0))
print(random.uniform(0.0, 1.0))
print(random.uniform(0.0, 1.0))
Run that seeded block again and it will emit the same sequence in the same order.
Where seeding belongs
Seeding is most useful in places where deterministic behavior is more important than fresh randomness:
- Unit tests that verify transformations, thresholds, or validation logic.
- Bug reproduction when a rare generated value triggers a crash.
- Examples and tutorials where stable output helps readers verify behavior.
- Benchmark harnesses that should compare implementations under the same random inputs.
Developers preparing for analytics and modeling interviews run into this often because reproducibility is one of the fastest ways to separate a clean experiment from a noisy one. This article on preparing for a data science interview covers adjacent habits that hiring teams tend to notice.
Prefer local generators in larger systems
Global module state becomes a problem in bigger codebases. If one test or module calls random.seed(), it can affect unrelated code that also depends on random.
A better pattern is to create dedicated generator instances.
import random
rng = random.Random(42)
values = [rng.uniform(0.0, 1.0) for _ in range(3)]
print(values)
This keeps the sequence local to the component that owns it.
Why separate generators help
| Concern | Global random module | random.Random() instance |
|---|---|---|
| Isolation | Shared state | Local state |
| Debugging | Harder in large apps | Easier to reproduce component behavior |
| Test safety | One seed can affect many tests | Each test can own its own generator |
Keep randomness injectable. A function that accepts an RNG object is easier to test than one that reaches into global state.
That pattern scales well in services, pipelines, and simulation code where multiple subsystems need independent control over randomness.
Common Pitfalls and Critical Edge Cases
Most problems with Python Random Uniform don't come from syntax. They come from assumptions. Two of them matter more than the rest: endpoint behavior and geometric misuse.
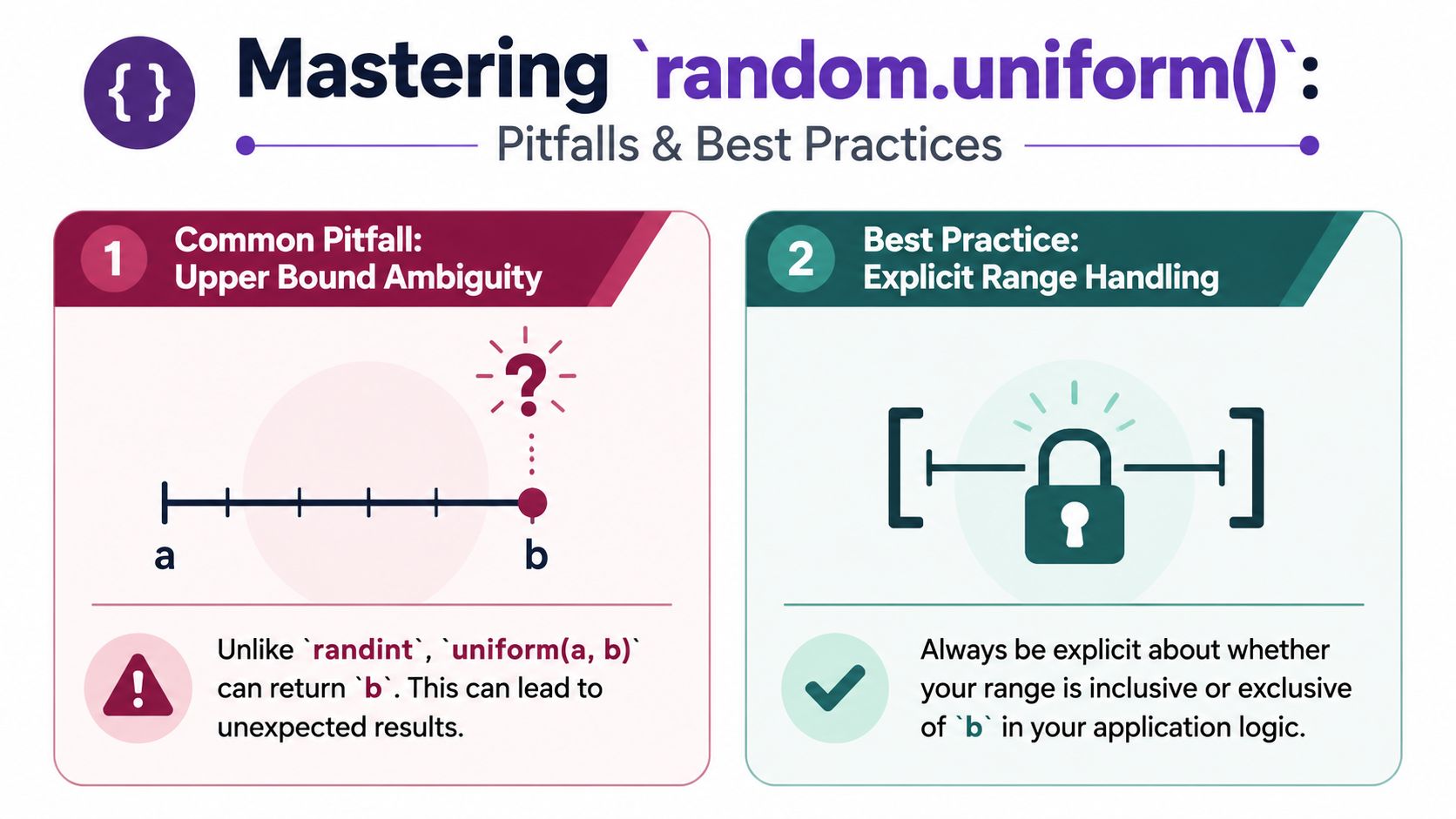
The upper bound is not a hard guarantee
Python's standard library documentation states that random.uniform(a, b) returns a value where a <= N <= b when a <= b, but it also notes that the upper bound b may or may not be included because of floating-point rounding in the implementation a + (b-a) * random() in the official Python random documentation.
That wording matters. Many articles flatten it into “inclusive of both endpoints,” which is too simple for production reasoning. The statistical distribution is uniform across the interval, but floating-point representation affects exact endpoint behavior.
What this means in code
If the application only needs “some float in this range,” random.uniform() is usually fine. If the application needs a strict half-open interval like [a, b), or if exact endpoint inclusion changes logic branches, then the function alone isn't enough specification.
Examples where this matters:
- Interval membership checks where equality with
btriggers a different branch - Grid generation where duplicate endpoint handling changes bin assignment
- Simulation boundaries where exact edge values are reserved or invalid
Operational advice: Don't build correctness on an assumption that
bwill never occur, or that it must occur. Encode the boundary rule explicitly in the surrounding logic.
A common defensive pattern is to validate or clamp based on the application's contract instead of trusting the generator to express it perfectly.
import random
def sample_half_open(low: float, high: float) -> float:
x = random.uniform(low, high)
if x == high:
return low
return x
That example isn't mathematically elegant, but it illustrates the point: if the system requires a special boundary rule, the code should state that rule directly.
A one-dimensional uniform float does not solve geometry
This is the second major mistake. Developers often use random.uniform() to sample geometric spaces and assume the result is uniform in the target shape. That's wrong more often than it's right.
A common error is sampling a radius uniformly and an angle uniformly to generate points in a disk. The circle tutorial referenced in the prompt makes the issue clear: sampling radius and angle uniformly creates a higher density of points near the center, and the correct radius should come from the square root of a uniform random variable in the disk sampling explanation.
Sampling a circle wrong versus right
| Sampling a Circle Wrong vs. Right | Wrong | Right |
|---|---|---|
| Radius choice | Uniform radius | Radius based on square root of a uniform random value |
| Point density | Biased toward center | Uniform across area |
| When it fails | Disk and annulus area sampling | Avoids area bias |
Role of random.uniform() | Misapplied as full solution | Still useful as one input to the correct transform |
A naive implementation looks like this:
import math
import random
r = random.uniform(0.0, 1.0)
theta = random.uniform(0.0, 2.0 * math.pi)
x = r * math.cos(theta)
y = r * math.sin(theta)
It looks reasonable. It isn't uniform over the disk.
The corrected pattern applies the square root to the random radius input:
import math
import random
u = random.uniform(0.0, 1.0)
theta = random.uniform(0.0, 2.0 * math.pi)
r = math.sqrt(u)
x = r * math.cos(theta)
y = r * math.sin(theta)
This is the production lesson: random.uniform() is a scalar building block. It doesn't define the geometry for you.
Directional data needs different tools
The Python documentation also makes clear that the random module contains distributions for specific modeling needs. For directional sampling problems, vonmisesvariate() may be a better fit than forcing uniform() into a role it doesn't own. The right generator depends on the variable's meaning, not on the convenience of the function name.
Developers get the best results when they ask two questions before coding:
- Is this variable scalar, spatial, or directional?
- Does the boundary behavior matter to correctness, or only to plausibility?
Those two checks prevent most random.uniform() misuse before it gets into a code review.
When to Use NumPy Instead of Random
The standard library is a good default for isolated values and lightweight scripts. It stops being the best tool when the code needs arrays, batch generation, or numerical workflows that already live in NumPy.
The practical difference isn't philosophical. It's about shape and ergonomics. random.uniform() returns one float at a time. numpy.random.uniform() is built for array-oriented work.
The decision point
If the code is generating a handful of values for tests or app logic, the standard library is easier to read and has no extra dependency. If the code is generating vectors, matrices, simulation batches, or feature arrays, NumPy usually fits better because the API works naturally with array shapes.
That matters in data science and ML pipelines, where downstream code often expects ndarray inputs from the start. Readers working in that ecosystem may also find this roundup of machine learning and data science websites useful for keeping tools and workflows current.
Comparison table
| Feature | random.uniform | numpy.random.uniform |
|---|---|---|
| Primary output | Single float | Array-oriented output |
| Best use case | App logic, simple scripts, tests | Numerical computing, batch generation, data workflows |
| Dependency | Standard library | Requires NumPy |
| Vectorization | No | Yes |
| Fits naturally with | Plain Python control flow | Array pipelines and scientific code |
What works well with each
- Choose
random.uniformwhen generating one value at a time inside request handlers, helper functions, CLI scripts, or test setup code. - Choose
numpy.random.uniformwhen the surrounding code already uses NumPy arrays, matrix math, or batch transforms. - Switch early if the code starts with loops whose only job is filling arrays.
The same caution about modeling still applies. A vectorized API doesn't fix a bad probability model. As noted earlier, a common but incorrect method for generating points uniformly in a disk is to sample radius and angle uniformly, which creates excess density near the center. The correct method uses a radius proportional to the square root of a uniform random variable in the disk sampling discussion. NumPy can make that faster, but it doesn't change the math.
Picking NumPy over
randomis a software design choice. Picking the right distribution is a modeling choice. Those are separate decisions, and both matter.
A common guideline is simple. Use the standard library when randomness is local and scalar. Use NumPy when randomness is part of a numerical pipeline.
Teams hiring for Python, data science, quant, cloud, and engineering leadership roles often need people who can move past syntax and reason about production trade-offs. nexus IT group connects employers with experienced technology professionals who can do exactly that, from implementation details like reproducible simulations to broader platform and data engineering work.