
Data scientists aren’t entering a fad. They’re entering a labor market the U.S. Bureau of Labor Statistics projects will grow 34% from 2024 to 2034, with about 23,400 openings each year on average over the decade (BLS data scientist outlook).
That number changes the conversation. A data science career isn’t just about learning Python and hoping for the right title. It’s a strategic path that sits at the intersection of analytics, software, machine learning, and business decision-making. Companies don’t hire data scientists to admire models. They hire them to improve forecasting, reduce risk, sharpen product decisions, and build systems that keep producing value after the first analysis is done.
For job seekers, that means the upside is real, but so is the bar. For hiring managers, it means the market keeps rewarding clear role design and punishing vague job descriptions. The strongest teams know exactly when they need an analyst, a data scientist, a machine learning engineer, or a data engineer. The strongest candidates know exactly which of those jobs they’re trying to win.
Table of Contents
- The Data Science Opportunity in 2026
- The Modern Data Scientist’s Role Explained
- Essential Technical and Soft Skills
- Mapping Your Career Progression and Salary
- Finding Your Niche Data Science Specialization
- Strategies for the Data Science Job Search
- Building Your Future-Proof Data Career
The Data Science Opportunity in 2026
Data scientist employment is projected to grow 34% from 2024 to 2034, with about 23,400 openings a year on average, as noted earlier. For candidates, that signals a field with real staying power. For hiring managers, it means competition for strong talent will remain high, especially in roles that sit close to revenue, product performance, risk, and automation.
From a recruiting seat, the market has changed in a way generic career guides often miss. Companies are no longer hiring “a data scientist” in the abstract. They are hiring for specific business problems. Recommendation systems. Forecasting. Fraud detection. Experimentation. Pricing. LLM evaluation. The title stays broad, but the work is getting narrower and more specialized.
That shift matters.
A data science career in 2026 is less about collecting a long list of tools and more about building a defensible combination of skills. Python plus experimentation design. SQL plus product analytics. Time-series modeling plus supply chain context. Classical machine learning plus MLOps discipline. Candidates who can tie their skills to a business domain are easier to place and usually more credible in interviews. Managers who define the specialization up front tend to make better hires.
AI is part of that equation. It has raised the floor for basic coding, analysis, and even model prototyping. It has not removed the need for judgment. Teams still need people who can choose the right problem, test whether a model should exist at all, spot weak assumptions, and explain risk to non-technical stakeholders. Those are the traits that hold up when tooling gets cheaper and faster.
Hiring gets difficult when employers ignore that reality. I still see job descriptions asking for deep statistics knowledge, production-grade engineering, stakeholder management, domain expertise, and senior-level communication in one mid-level hire. That usually creates two problems. Strong candidates opt out because the scope looks unrealistic. Weaker candidates apply because the company has not shown what success entails.
A good data science hire improves decision quality. A poor one produces analysis that never reaches production or changes a business process.
For professionals entering the field, the opportunity is real, but the safest path is not “learn everything.” Pick a lane that companies already fund, then build proof. For employers, the lesson is similar. Hire for the workflow and business outcome, not for an inflated wish list. Anyone following where data science roles are headed over the next decade can see the pattern. The profession is becoming more embedded in core operations, more specialized by use case, and more valuable for people who can combine technical skill with business judgment.
The Modern Data Scientist’s Role Explained
A modern data scientist is part analyst, part model builder, part product partner. The cleanest description is this. They act as a business translator, turning open-ended business questions into data work that can be tested, implemented, and improved.
Coursera notes that data scientists use programming, statistics, and data wrangling to create algorithms and data models that forecast outcomes, which is why the role increasingly centers on end-to-end model development rather than isolated analysis (Coursera data scientist skills guide).
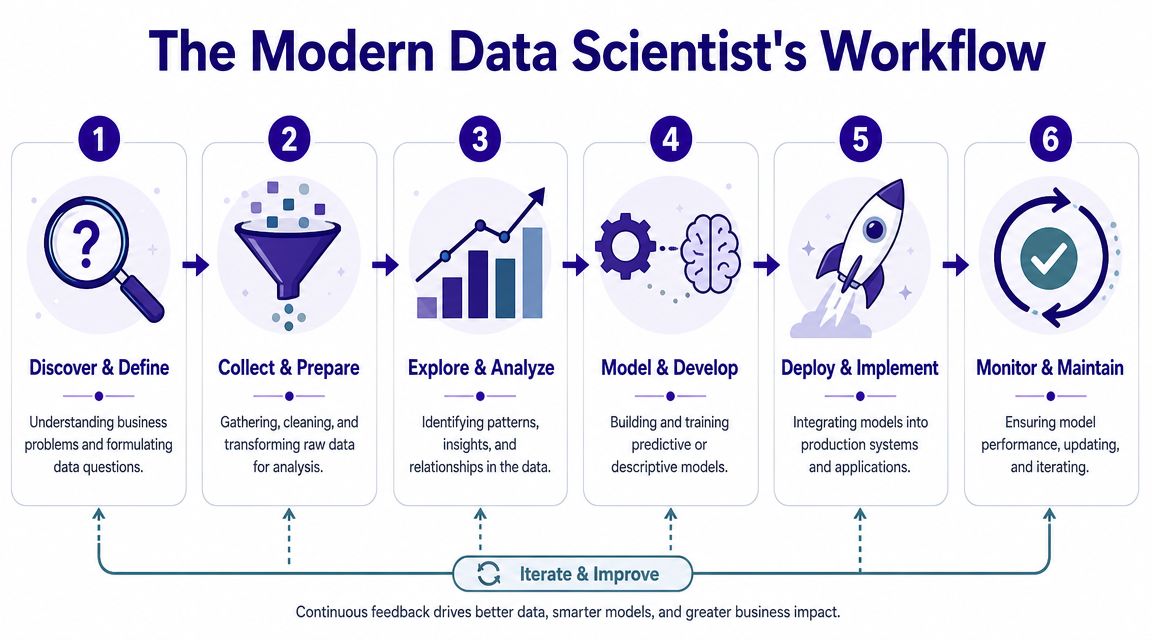
From business question to production outcome
The daily work usually starts before the code. A product lead asks why churn increased. A fraud team wants better detection. A finance leader wants demand forecasts that are reliable enough to plan against. The data scientist’s first job is to tighten that question. What outcome matters? What decisions will change if the model works? What data exists?
After that, the workflow becomes more technical:
-
Problem framing
A vague ask becomes a measurable objective. In this phase, weak projects are often exposed early. -
Data collection and preparation
Data rarely arrives in analysis-ready form. Teams pull from warehouses, logs, APIs, event streams, and operational systems. Then they clean joins, resolve missing fields, and define trustworthy inputs. -
Exploration and analysis
This stage looks for patterns, edge cases, and data quality problems. Good exploration prevents overconfident modeling later. -
Modeling
The right model depends on the task. Sometimes a simpler baseline is enough. Sometimes the job requires more complex machine learning. Strong practitioners know when complexity helps and when it only impresses other practitioners. -
Deployment
Many candidates overestimate their experience here. A notebook isn’t deployment. Production work means integration, monitoring, versioning, and clear ownership. -
Monitoring and iteration
Models drift. Inputs change. Business conditions change. Useful data scientists don’t disappear after launch.
Why the translator role matters
The stereotype says data scientists spend all day building models. In practice, much of the value comes from deciding what not to build, what to simplify, and how to communicate uncertainty to non-technical stakeholders.
Practical rule: If a candidate can explain model assumptions to a finance lead, an engineer, and a product manager without changing the core logic, that candidate usually understands the work.
Hiring managers often make the mistake of overweighting algorithms and underweighting operational judgment. Candidates make the opposite mistake. They present polished notebooks but can’t explain what business decision the work improved.
The strongest data science career paths come from mastering both sides. The technical side gets a model working. The translation side gets the model funded, adopted, and maintained.
Essential Technical and Soft Skills
The shortest way to evaluate readiness for a data science career is to ask two questions. Can this person do the work? Can this person make the work useful to other people? Most hiring mistakes happen when one side is present and the other isn’t.
Technical foundations that hold up on the job
A recruiter can spot shallow preparation quickly. Candidates often list every tool they’ve touched. Employers often ask for every tool they’ve heard of. Neither approach works. The durable skill set is smaller and more practical.
-
Programming in Python or R
Python dominates most production-facing data science workflows because it connects cleanly to machine learning libraries, data pipelines, and engineering environments. R still matters in some statistical and research-heavy settings. What matters most is whether the candidate can write maintainable analysis code, not whether they’ve memorized syntax. -
SQL for real data access
SQL is not optional. Even strong modelers get screened out when they can’t join tables, inspect data quality, or build reproducible extracts. Many jobs fail at the data retrieval stage long before they reach machine learning. -
Statistics and experiment thinking
Teams need people who understand distributions, sampling issues, bias, variance, and model evaluation. They also need people who know when a metric is misleading. Fancy tooling doesn’t rescue weak statistical judgment. -
Data wrangling and feature work
Much of the job is turning messy operational data into usable signals. This is less glamorous than modeling and far more important in most business environments. -
Machine learning fundamentals
Candidates should understand supervised learning, common model families, validation logic, and trade-offs between interpretability and performance. They don’t need to claim expertise in every method. They do need to show they can choose a reasonable approach for a defined problem. -
Cloud and production awareness
Teams increasingly expect data scientists to work near cloud infrastructure and production systems. That doesn’t mean every data scientist needs to be a platform engineer. It does mean they should be comfortable collaborating in environments that use tools like AWS, Azure, or Google Cloud, along with version control and workflow orchestration.
Soft skills that separate solid hires from risky ones
Technical skill gets interviews. Soft skill often decides whether someone becomes trusted inside a business.
A strong data scientist communicates trade-offs without hiding behind jargon. That’s not presentation polish. It’s operational value. If leaders can’t understand the recommendation, they won’t act on it. If engineers can’t understand the constraints, they won’t implement it.
Consider the soft skills that tend to matter most:
-
Stakeholder communication
Data scientists regularly work with product managers, finance leads, operations teams, and engineering partners. They need to adapt the message without diluting the logic. -
Business framing
Good candidates connect work to revenue, cost, risk, experience, or speed. Weak candidates describe tools. Strong ones describe decisions. -
Structured problem-solving
Employers trust people who can decompose a messy request into assumptions, inputs, risks, and next steps. -
Prioritization
Not every problem deserves a model. Not every model deserves deployment. Practical judgment is a differentiator. -
Documentation and handoff discipline
If only one person understands the notebook, the team has a fragility problem.
Teams usually regret hiring for technical flash when the role actually needed reliability, judgment, and communication.
For candidates, the practical move is to build evidence of both categories. A portfolio should show code, but also problem framing, metric choice, and a clear written explanation of business relevance. For employers, interview loops should test both categories on purpose. If the hiring process only checks syntax and theory, it won’t identify who can operate inside a real business.
Mapping Your Career Progression and Salary
A data science career usually broadens before it narrows. Early roles focus on execution. Later roles add influence, system design, mentoring, and strategic ownership. Candidates who understand that shift make better career moves. Hiring managers who structure roles around it retain stronger teams.
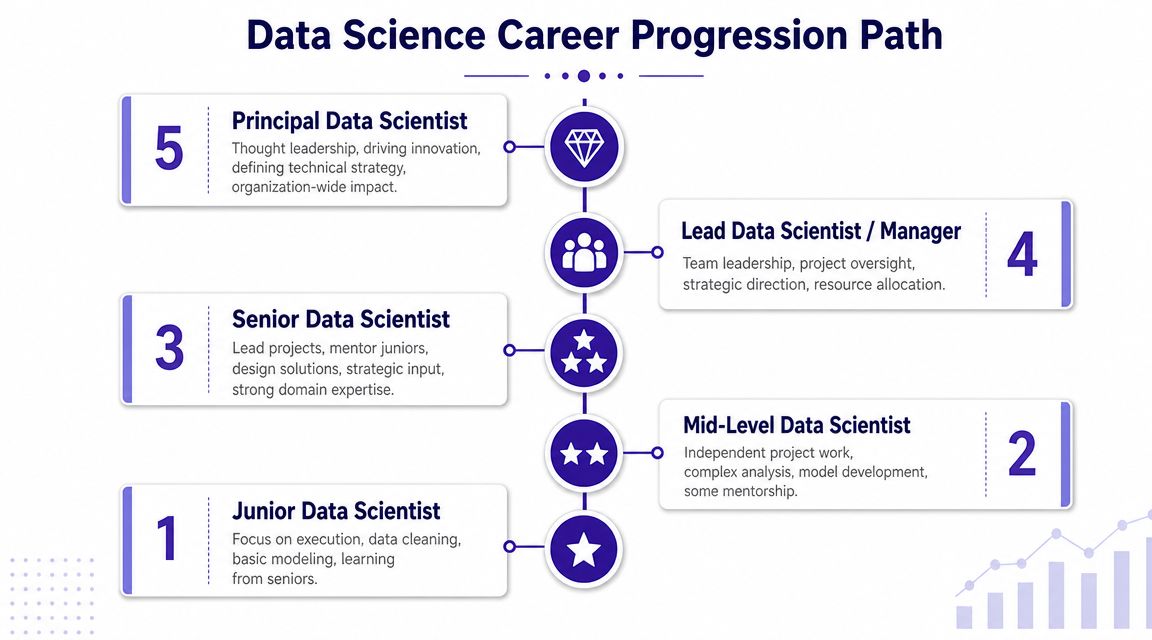
How responsibility changes at each level
Junior Data Scientist
This level is about learning how work gets done in a business setting. Juniors often spend more time on cleaning data, exploratory analysis, basic model implementation, and supporting senior team members. The best junior hires show coachability, clean thinking, and comfort with ambiguity. They don’t need to know everything. They do need to be usable.
Mid-level Data Scientist
At this stage, independence matters more. Mid-level practitioners can scope pieces of work, run analyses without constant supervision, and make reasonable decisions about methods. They usually start owning projects with visible business outcomes and become more reliable cross-functional partners.
Senior Data Scientist
Senior people lead. That doesn’t always mean direct reports. It usually means project ownership, technical direction, model design choices, mentoring, and credibility with stakeholders. Seniors are often the difference between a team that experiments and a team that ships.
Lead Data Scientist or Manager
This layer adds people coordination, roadmap influence, prioritization, and delivery oversight. Some companies split leadership into management and principal tracks. Others blur the line. Either way, the role shifts from individual output toward team output.
Principal Data Scientist
Principal-level work is broad, high-impact, and often organization-wide. These professionals shape technical strategy, guide difficult decisions, define standards, and influence where the company invests in data capability.
What salary data suggests about progression
Compensation reflects that growing scope. A 2026 labor-market analysis found that 32% of data science jobs offered salaries between $160,000 and $200,000, and the average U.S. salary was around $166,000 (2026 data scientist salary analysis). That doesn’t mean every role pays at that level. It does show why experienced candidates become difficult to replace once they can own work across modeling, business context, and delivery.
The BLS also reports that the median annual wage for data scientists was $112,590 in May 2024 and notes that the role typically requires at least a bachelor’s degree in mathematics, statistics, computer science, or a related field, with some employers preferring advanced degrees. That combination of compensation and educational expectations helps explain why employers compete hard for proven talent and why the field keeps attracting career changers who already have technical foundations.
A practical hiring read is straightforward:
| Level | Main value to the business | Common hiring signal |
|---|---|---|
| Junior | Reliable execution | Learning speed and fundamentals |
| Mid-level | Independent delivery | Strong project ownership |
| Senior | Technical and stakeholder leadership | Repeatable business impact |
| Lead or Principal | Organizational leverage | Strategy, mentoring, and system thinking |
For employers benchmarking roles, data science salary expectations across levels can help frame compensation discussions. For candidates, the career lesson is simpler. The largest jumps tend to come when responsibilities expand from analysis alone into ownership, communication, and production impact.
Finding Your Niche Data Science Specialization
One of the most common hiring problems in this field is title confusion. A company says it wants a data scientist, then describes a data engineer. A candidate says they want machine learning work, then applies to dashboard-heavy analyst roles. Precision matters because these jobs solve different problems.
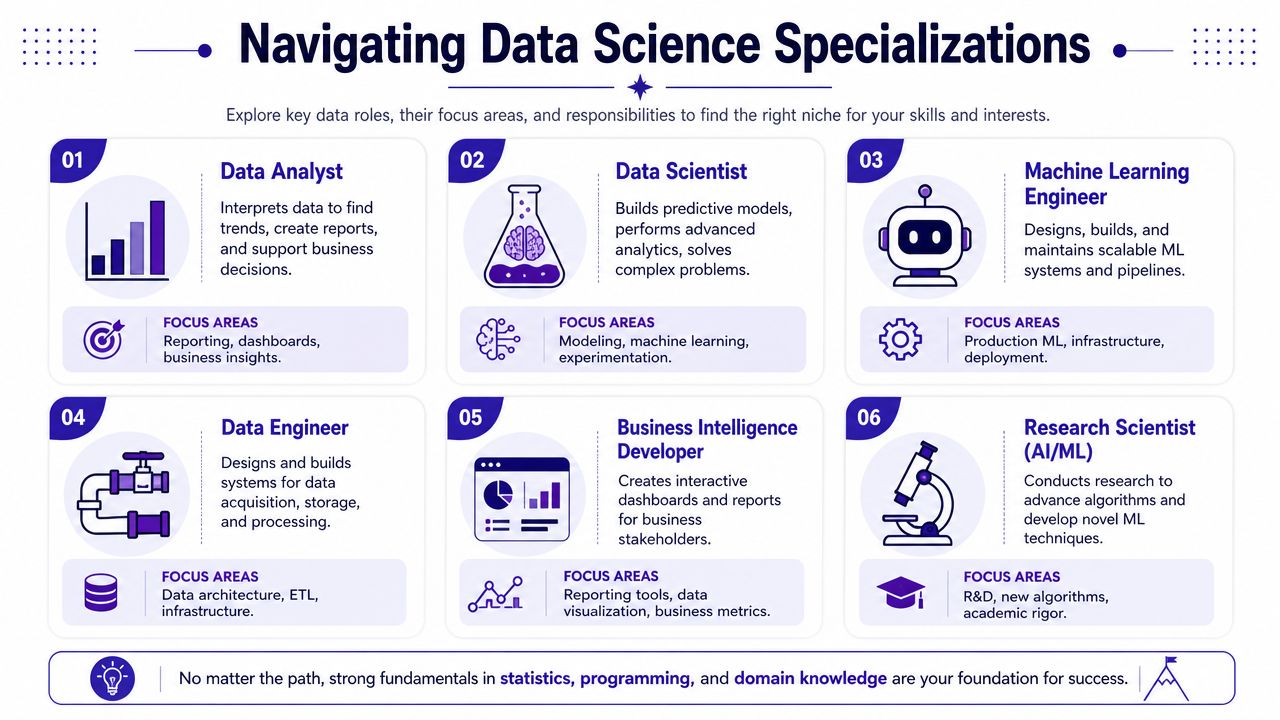
How the roles differ in practice
A useful way to separate roles is by the core question each one answers.
Data Analyst
This role usually answers, “What happened, and what does it mean?” Analysts work close to reporting, trends, dashboards, and business performance. They often spend more time in SQL, BI tools, and stakeholder requests than in predictive modeling.
Data Scientist
This role usually answers, “What is likely to happen, what drives it, and what should be tested?” Data scientists move beyond descriptive reporting into modeling, experimentation, forecasting, segmentation, and decision support. They need stronger statistical depth and more comfort with ambiguous business problems.
Data Engineer
This role answers, “How does data move reliably from source to system to user?” Data engineers build pipelines, storage layers, transformations, and infrastructure that keep data usable at scale. Without them, most analytics and modeling work becomes fragile.
Machine Learning Engineer
This role answers, “How does the model run reliably in production?” ML engineers focus on serving, deployment, performance, monitoring, and scalable systems for machine learning. In some companies, data scientists prototype and ML engineers productionize. In others, one person handles both. The split depends on team maturity.
Business Intelligence Developer
This role sits close to reporting systems and dashboard design. The emphasis is less on predictive modeling and more on making metrics accessible, consistent, and actionable for business teams.
Research Scientist in AI or ML
This role sits furthest toward algorithm development and advanced experimentation. It's usually a fit for environments that value novelty, publication-style rigor, or deep specialization in model design.
Data Science Role Comparison
| Role | Primary Focus | Key Tools | Core Deliverable |
|---|---|---|---|
| Data Analyst | Reporting, trends, business insight | SQL, Excel, Tableau, Power BI | Dashboards, reports, decision support |
| Data Scientist | Modeling, experimentation, prediction | Python, R, SQL, notebooks, ML libraries | Predictive models, experiments, recommendations |
| Machine Learning Engineer | Production ML systems | Python, CI/CD tooling, cloud platforms, model serving tools | Deployed and maintained ML services |
| Data Engineer | Data architecture and pipelines | SQL, Spark, orchestration tools, cloud data platforms | Reliable data pipelines and infrastructure |
| Business Intelligence Developer | Metric delivery and visualization | Power BI, Tableau, SQL, semantic layers | Executive dashboards and reporting frameworks |
| Research Scientist | Novel algorithms and advanced ML research | Python, research frameworks, statistical tooling | New methods, prototypes, technical innovation |
How candidates and employers should use these distinctions
Candidates should choose a niche based on preferred work, not title prestige. Someone who enjoys business partnering, dashboards, and direct stakeholder interaction may thrive as an analyst or BI developer. Someone who likes experimentation and predictive questions may fit the data science career path more naturally. Someone who cares about platform reliability, pipelines, and scale may be better suited for data engineering or ML engineering.
Hiring managers should write job descriptions around deliverables. Don't ask for deep experimentation, dashboard ownership, pipeline engineering, and production MLOps in one role unless the team expects a hybrid position and is willing to compensate for it.
The fastest way to lose strong applicants is to post a title for one role and describe the workload of three.
The best specialization decisions come from clarity. What problem needs solving? What work will this person do weekly? What handoffs exist? Once those answers are clear, the right talent pool becomes much easier to find.
Strategies for the Data Science Job Search
Hiring teams still reject strong data candidates for avoidable reasons. Candidates present a toolbox instead of business results. Employers screen for textbook knowledge and miss the judgment required on the job.
AI is changing the hiring bar. Routine coding, basic analysis, and first-draft modeling are easier to automate than they were even a few years ago. What holds value longer is the ability to define the problem, choose the right method for the stakes, explain trade-offs, and turn analysis into a decision a business can act on. That is the defensible part of a data science career, and it should shape both the job search and the hiring process.
What candidates should do now
Candidates who get interviews in this market usually make one thing easy for employers to see. They show how their work changed an outcome.
A small portfolio is enough if it proves judgment. One forecasting project with messy data, realistic assumptions, and a clear recommendation beats five polished notebooks copied from tutorials. Show the business question, the data issues, why you chose a method, how you evaluated it, and what decision the result would support. That format also signals where you fit best. Experiment design points toward product or growth work. Forecasting and planning point toward operations or finance. Risk models and explainability often align with regulated sectors.
Resumes should follow the same rule. Lead with outcomes, scope, and context. Tool lists belong lower on the page. Hiring managers want to know whether you improved a process, reduced manual reporting time, supported pricing, increased forecast accuracy, or helped a team act faster with better information.
Interview prep also needs to match how real teams hire. Good interviewers rarely care whether a candidate can recite every formula from memory. They care whether the candidate can reason under constraints. Why use a simpler model here? What would break in production? When is more data more useful than more model complexity? Candidates who want focused practice should review this guide on preparing for a data science interview.
One more pattern matters. Generalist profiles can still win, but domain direction is becoming more important. A candidate who understands claims data, supply chain volatility, fraud signals, or subscription churn is easier to place and often easier to trust.
Candidates move faster when they connect a technical choice to cost, risk, revenue, or customer impact.
What hiring managers should stop doing
The weakest hiring loops create their own talent shortage. I see it constantly in recruiting. A company posts for a “data scientist,” asks for BI reporting, experimentation, feature engineering, deployment, and executive storytelling, then wonders why the right people drop out or ask for senior-level compensation.
Three hiring changes improve results quickly:
-
Define the job by actual weekly work
Spell out whether the role is modeling-heavy, analytics-heavy, experimentation-heavy, or tied to production systems. Clear scope improves applicant quality more than adding another requirement. -
Test judgment, not trivia
Use interviews built around a messy dataset, a business case, or a flawed model that needs critique. Those exercises show how someone thinks, which matters more than whether they remember a niche definition. -
Screen for defensible skills
Ask how the candidate handled ambiguity, data quality problems, stakeholder disagreement, or model trade-offs. AI tools can help write code. They do not replace prioritization, decision quality, or trust with business partners.
Communication should be assessed directly. Ask candidates to explain a result to a non-technical stakeholder, defend a recommendation, or describe when they would not deploy a model. That is often the difference between a hire who ships useful work and one who stays stuck in analysis.
Companies that need help calibrating the role or reaching specialized candidates sometimes work with recruiting firms such as nexus IT group alongside internal hiring managers and technical interviewers. The value is usually not resume volume. It is role clarity, tighter screening, and access to candidates whose backgrounds match the actual work.
Building Your Future-Proof Data Career
A durable data science career won't come from chasing every new tool. It will come from building a stack of skills that remains useful as tools get easier to use. Technical depth still matters. So do SQL, statistics, modeling, and software habits. But those skills hold their value longer when they're paired with domain expertise, experimentation discipline, and the ability to influence decisions.
For candidates, the practical path is to choose a specialization deliberately, build a portfolio that shows real thinking, and get comfortable explaining trade-offs to non-technical audiences. For employers, the practical path is just as clear. Define the role correctly, assess for real work, and stop treating every data hire as an interchangeable “unicorn.”
The profession will keep changing as AI tools automate more routine work. That doesn't make data scientists less relevant. It raises the value of the people who can frame the problem, test the right approach, and turn technical output into business action.
The winners in this market won't be the people who know the most libraries. They'll be the professionals and teams who know how to create decisions others can trust.
Whether a company is hiring for a hard-to-fill data science role or a candidate is trying to position the next move, nexus IT group offers staffing and recruiting support focused on specialized technology talent, including data science, AI, machine learning, and data engineering.