
The AI market isn’t growing because companies suddenly learned how to train novel models from scratch. It’s growing because businesses are finding ways to put AI into products, workflows, service operations, and internal tools. One industry summary projects the global AI market at $260 billion in 2025 and $1.2 trillion by 2030, and notes that 78% of organizations worldwide reported using AI in 2024, up from 55% in 2023 (AI market and adoption figures).
That scale changes the hiring conversation. The central question is no longer whether AI matters. It’s who turns a promising model, or a third-party foundation model API, into something stable enough for customers, employees, and executives to rely on.
That job belongs to the AI engineer. For hiring managers, that means defining the role correctly before opening a req. For candidates, it means understanding that the market usually rewards production judgment more than notebook demos.
Table of Contents
- The Hidden Engine Behind the AI Boom
- Defining AI Engineering Beyond the Buzzwords
- AI Engineer vs ML Engineer vs Data Scientist
- The AI Engineering Workflow in Practice
- The Modern AI Engineer’s Skill Set and Toolkit
- A Guide to Hiring and Becoming an AI Engineer
- How Nexus IT Group Bridges the AI Talent Gap
The Hidden Engine Behind the AI Boom
Most companies talk about AI in terms of models. The actual bottleneck is usually everything around the model.
An enterprise may have a strong use case, budget, executive support, and access to capable models from OpenAI, Anthropic, Google, or open-weight alternatives. None of that guarantees a working system. Someone still has to connect data sources, build application logic, define failure handling, control latency, expose APIs, manage environments, and keep the output useful after launch.
Why the role matters now
The market numbers make the timing obvious, but the operational reality matters more. As AI moves into support tools, internal copilots, document workflows, search, recommendations, fraud review, and software delivery, teams need people who can ship AI as software, not just discuss it as research.
That’s where many hiring plans go wrong. A company decides it needs “an AI person” and writes a description that blends data science, model research, backend engineering, MLOps, prompt design, DevOps, and product strategy into one impossible profile. The result is slow hiring and unclear expectations after the person joins.
Practical rule: If the business problem involves reliability, integration, observability, and change management, the conversation has moved into AI engineering.
What hiring managers and candidates should take from this
For hiring managers, the rise of AI engineering means the job title should map to business constraints. If the team is building customer-facing features on top of hosted models, the role should emphasize orchestration, testing, infrastructure, and governance. If the team is training proprietary models, the balance shifts, but production ownership still matters.
For candidates, this is good news. The strongest profiles in this market often come from adjacent backgrounds: software engineering, platform engineering, ML engineering, data engineering, or cloud infrastructure. Many successful AI engineers didn’t start as AI specialists. They became valuable because they could make complex systems dependable.
A useful way to answer the question “What is AI engineering?” is this: it’s the discipline that turns AI capability into operational capability.
Defining AI Engineering Beyond the Buzzwords
AI engineering is easiest to understand when it’s separated from the hype. It isn’t just “building with AI,” and it isn’t limited to training models.
According to Pensiero’s definition of AI engineering, AI engineering is best understood as the production discipline that turns AI models into reliable software systems. It combines systems engineering, software engineering, and human-centered design to manage the full lifecycle, from data ingestion and model integration to API exposure and post-deployment monitoring.
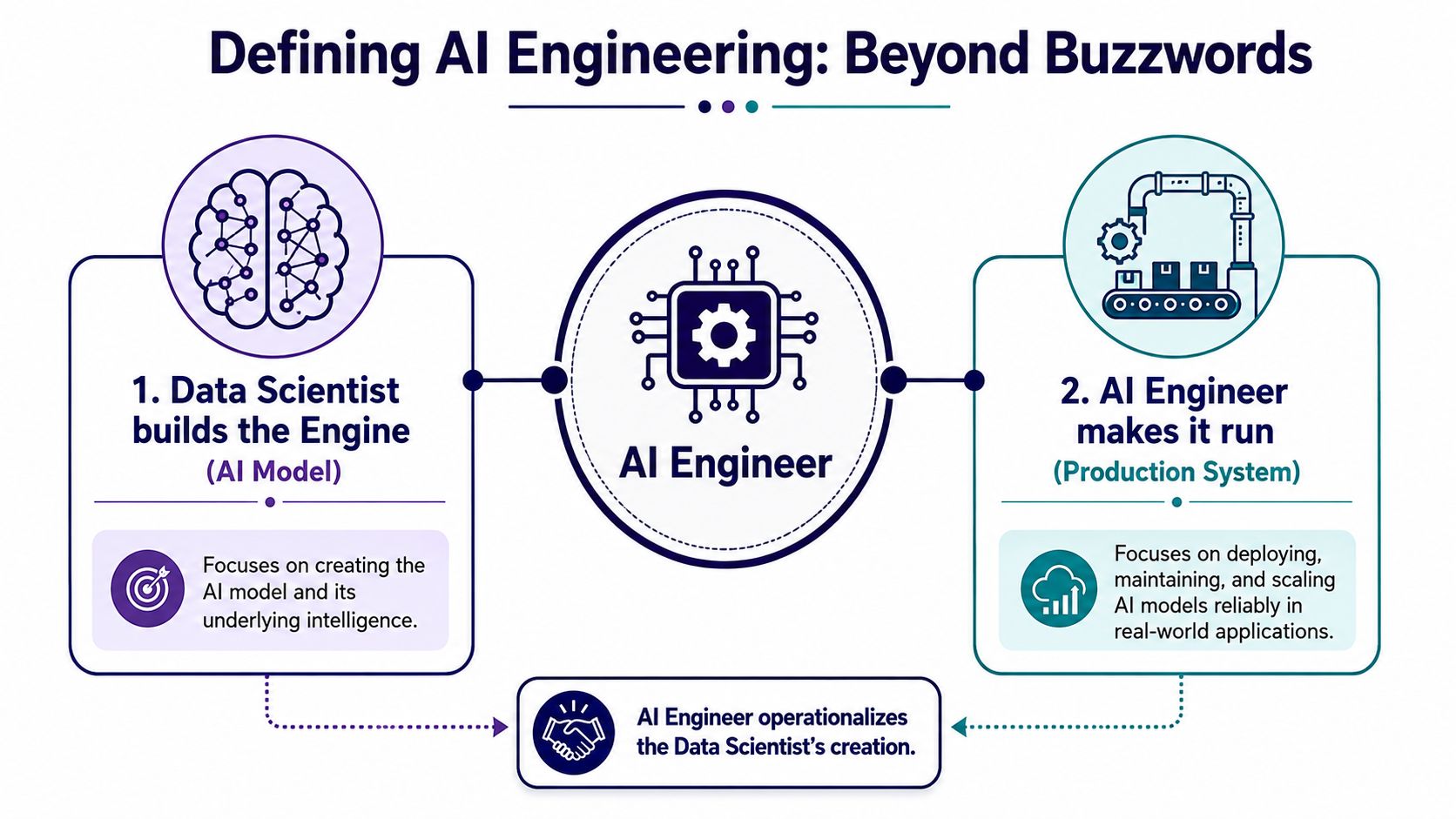
The car-and-engine analogy still works
A data scientist or research team may produce the engine. They tune the model, test approaches, and improve task performance.
The AI engineer builds the car around it. That includes the intake systems, controls, safety checks, serviceability, and road-readiness. In software terms, that means pipelines, APIs, auth, retries, observability, deployment workflows, evaluation harnesses, and feedback loops.
A good model in a notebook can still fail in production for ordinary reasons:
- Input mismatch because real user data doesn’t resemble clean test data
- Latency issues because inference is too slow once traffic spikes
- Integration problems because upstream systems send incomplete or inconsistent payloads
- Reliability failures because downstream services, vector stores, or third-party APIs become unstable
- Operational blind spots because nobody can explain what changed when quality drops
What the discipline actually owns
In practice, AI engineering usually covers a connected set of responsibilities:
- Data movement and preparation so the application receives usable, current inputs
- Model or API integration so the AI component can be called safely and consistently
- Application logic that wraps prompts, retrieval, ranking, validation, and business rules
- Deployment and infrastructure using tools like Docker, Kubernetes, Terraform, AWS, Azure, or Google Cloud
- Monitoring and maintenance so teams catch regressions, cost spikes, or quality drift before users complain
Strong AI engineering doesn’t treat the model as the product. It treats the model as one dependency inside a larger production system.
That distinction matters because many teams still hire for novelty when they really need operational maturity. The companies that get value from AI fastest usually don’t chase the most exotic model work first. They solve narrow business problems with systems they can maintain.
AI Engineer vs ML Engineer vs Data Scientist
Most hiring confusion arises because the titles overlap, the tools overlap, and some companies use them interchangeably. That doesn’t mean they’re the same role.
MIT’s framing highlights a key issue for employers: the distinction between AI engineering and adjacent roles often gets blurred, even though the AI engineer’s practical contribution is owning the full lifecycle of model selection, API integration, data pipelines, deployment, monitoring, and stakeholder communication (MIT discussion of AI engineering responsibilities).
Role comparison at a glance
| Dimension | AI Engineer | ML Engineer | Data Scientist |
|---|---|---|---|
| Primary goal | Turn AI capability into a reliable product or internal system | Build and optimize machine learning systems and model-serving workflows | Extract insight, test hypotheses, and improve decisions with data |
| Main focus | End-to-end production lifecycle | Model packaging, training pipelines, feature pipelines, serving | Analysis, experimentation, modeling, business interpretation |
| Typical work | API integration, orchestration, prompt/application design, deployment, monitoring, governance | Training infrastructure, feature engineering support, model optimization, serving performance | Exploration, forecasting, segmentation, experimentation, reporting |
| Deliverables | Production AI services, copilots, agent workflows, monitored applications | Reproducible training pipelines, model artifacts, feature stores, scalable inference endpoints | Analyses, dashboards, experiments, model prototypes, recommendations |
| Success measure | Reliability, usability, latency, cost control, fit with workflow | Model performance, reproducibility, serving efficiency | Business insight, model validity, decision support |
| Common failure mode | Great demo, weak production controls | Technically sound pipeline with weak product integration | Accurate analysis that never becomes an operational system |
Where the boundaries show up on real teams
A data scientist may prove that a classification approach is directionally useful. An ML engineer may formalize training and model-serving workflows. The AI engineer takes responsibility for getting that capability into a real product or process where non-technical users depend on it.
That difference becomes sharper in foundation model work. If a team is building a support copilot, document assistant, or internal search tool, there may be little custom model training at all. The hard part is often choosing a model, structuring prompts, adding retrieval, managing output quality, handling permissions, and instrumenting the stack.
For employers trying to scope the role, a practical reference point is this machine learning engineer job description. It helps clarify where classic ML engineering stops and where broader AI system ownership begins.
A practical hiring test
Ask a simple question: who owns the system after the prototype works?
If the answer includes rollout planning, service integration, fallback logic, stakeholder alignment, evaluation in live conditions, and production monitoring, that’s usually AI engineering. If the role mostly centers on training workflows, model tuning, and feature pipelines, it’s closer to ML engineering. If the work is centered on analysis and experimentation, it’s likely data science.
The AI Engineering Workflow in Practice
The day-to-day workflow of an AI engineer looks less like isolated experimentation and more like systems delivery. The model matters, but the surrounding pipeline usually determines whether the project survives contact with real users.
Google’s overview is useful here because it frames AI as a data- and infrastructure-dependent system, not a purely algorithmic one. That’s why AI engineers build reliable pipelines and optimize deployment infrastructure so models can serve predictions efficiently at scale, especially for applications built on foundation models (Google explanation of AI as a data and infrastructure system).
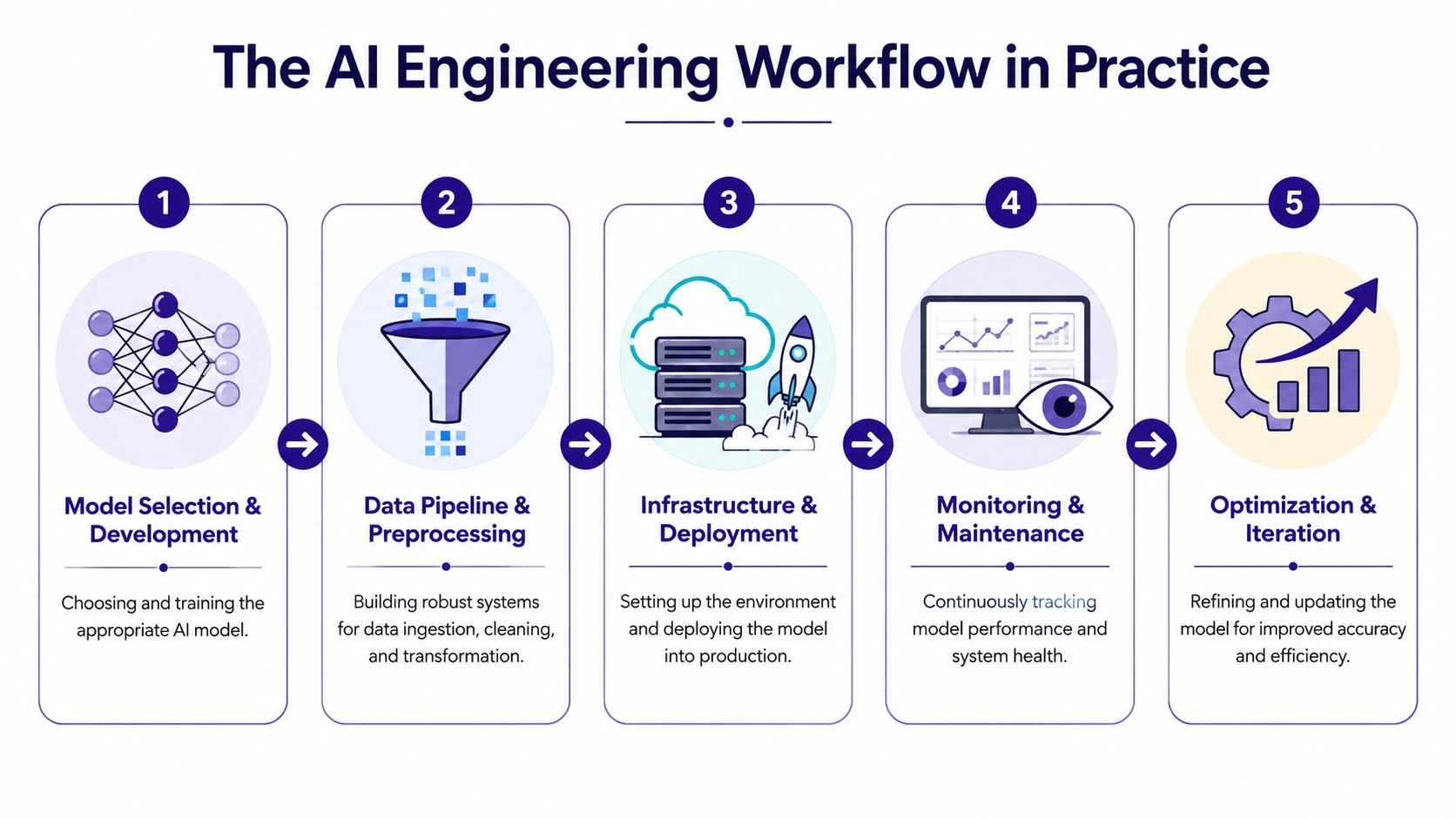
A typical production workflow
An AI engineering workflow often moves through these stages:
-
Problem framing
The team defines the user task, acceptable failure modes, and where AI should help versus where deterministic logic should stay in control. -
Model choice
Engineers decide whether the use case needs a hosted foundation model, an open model in a managed environment, or an existing internal model. This decision is rarely just technical. Security, budget, latency, and procurement all matter. -
Data pipeline setup
Data gets ingested, cleaned, transformed, labeled if needed, permissioned, and routed into the application path. In retrieval-based systems, this may also include chunking, indexing, and refresh logic. -
Application integration
The AI component gets wrapped with APIs, business logic, tool use, retries, prompt templates, validation layers, and user experience constraints. -
Deployment
The system moves into a controlled runtime with environment management, secrets handling, autoscaling policies, access control, and release procedures. -
Monitoring and iteration
Teams track output quality, latency, failures, user feedback, and dependency health. Then they update prompts, routing logic, context windows, retrieval rules, or model choice itself.
What works and what doesn’t
What works is a narrow first release. Teams that ship successfully usually start with a constrained use case, a clear fallback path, and aggressive observability.
What doesn’t work is treating AI like a black box plugin. Many projects stall because nobody defines test cases beyond “the demo looked good,” or because the team assumes a strong base model will compensate for weak application design.
Production AI succeeds when engineers instrument the whole path, not just the model call.
The operational checkpoints that matter
A strong workflow usually includes a short checklist before release:
- Failure handling with defaults, retries, escalation paths, or human review
- Data quality checks to catch malformed or stale inputs
- Evaluation criteria tied to the business task, not just generic model benchmarks
- Security review around access, retention, and sensitive data flow
- Cost controls so a popular feature doesn’t become an unplanned budget problem
That’s why the answer to “What is AI engineering?” has to include operations. Without them, AI stays in pilot mode.
The Modern AI Engineer’s Skill Set and Toolkit
The skill set has changed fast. A few years ago, many employers still pictured AI engineers as people who spent most of their time on custom model training. Today, many teams need something different: engineers who can evaluate, integrate, govern, and improve AI systems built on top of third-party or open models.
The role has shifted toward orchestration, evaluation, and governance, with growing emphasis on managing latency, cost, data privacy, and dependency on third-party APIs rather than inventing algorithms from scratch (overview of the role’s shift toward orchestration and risk management).
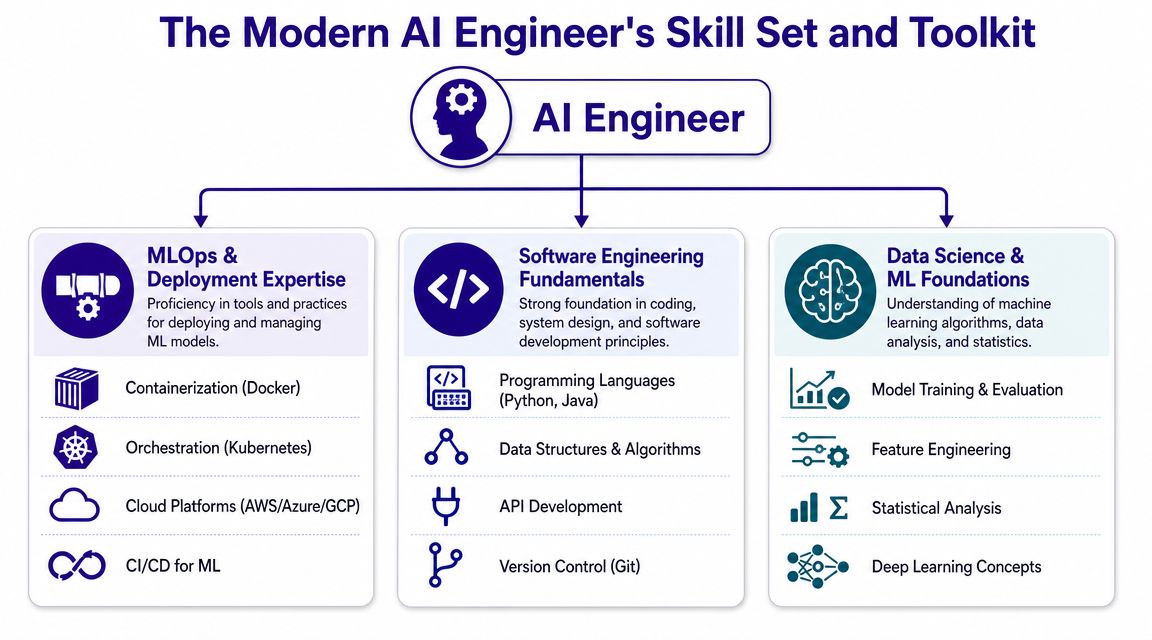
Three skill clusters that matter
Software and platform fundamentals
This remains the base layer. Teams still need engineers who can write clean Python, design services, build APIs, work with Git, debug production issues, and reason about distributed systems.
Useful tools often include FastAPI, Flask, Node.js services, PostgreSQL, Redis, Docker, Kubernetes, Terraform, and standard cloud services across AWS, Azure, or Google Cloud. A candidate who can’t explain service boundaries, observability, or deployment safety usually isn’t ready for production AI ownership.
AI application engineering
This is the newer center of gravity. The work often involves prompt design, tool orchestration, retrieval-augmented generation patterns, vector databases, evaluation harnesses, and model routing.
That may include products such as LangChain, LlamaIndex, OpenAI APIs, Anthropic APIs, Vertex AI, Azure AI services, Pinecone, Weaviate, Elasticsearch, or pgvector. The best engineers don’t just know the names. They know when not to use them.
Governance and operational judgment
Stronger candidates separate themselves. They think about logs, traceability, privacy boundaries, fallback behavior, vendor lock-in, and model change risk before the issue becomes visible to leadership.
Hiring signal: Ask candidates how they’d respond if output quality drops after a model provider updates behavior, but the application code hasn’t changed.
What hiring managers should screen for
A resume with every fashionable AI tool listed isn’t enough. Better indicators include:
- System ownership shown through deployed services, internal platforms, or customer-facing features
- Trade-off awareness around hosted models versus self-managed approaches
- Evaluation discipline beyond “it seemed accurate”
- Communication skills because AI projects often fail at the boundary between engineering, legal, security, and product teams
The modern toolkit matters. Judgment matters more.
A Guide to Hiring and Becoming an AI Engineer
The market for AI talent is active, but many searches still break down because employers ask for a research unicorn when they really need a production builder. Candidates make a similar mistake when they market themselves as model specialists even though their real advantage is systems delivery.

For hiring managers
Start with the business problem, not the title. If the company is deploying copilots, document workflows, or agentic systems on top of external models, the role should emphasize integration, reliability, evaluation, and governance.
A stronger AI engineer job description usually includes:
- Core mission tied to one or two business workflows, not broad “own all AI initiatives” language
- Technical scope such as Python services, cloud deployment, model APIs, vector search, data pipelines, CI/CD, and monitoring
- Operational expectations including quality evaluation, incident response, security review, and cross-functional communication
- Clear exclusions so the candidate knows whether model research, data science experimentation, or frontend ownership sit elsewhere
Interviewing should test judgment, not just syntax. Good questions include:
- System design prompt asking the candidate to design an internal knowledge assistant with permission-aware retrieval
- Failure scenario where response quality drops or a model provider rate-limits traffic
- Trade-off discussion on hosted APIs versus open models in a managed environment
- Monitoring question about what should appear on a production dashboard after launch
Leveling also matters. Junior candidates may contribute to pipelines, integration, and test coverage under guidance. Mid-level candidates should own services or workflows. Senior AI engineers should shape architecture, risk controls, vendor choices, and rollout strategy.
Comp planning is easier when employers benchmark the broader market using resources such as this AI engineer salary guide in the US.
For candidates
The strongest entry path usually comes from adjacent engineering work. Backend engineers, ML engineers, platform engineers, data engineers, and cloud-focused developers often move into AI engineering faster than candidates who only have coursework or toy demos.
Candidates should build a portfolio that shows production thinking:
- One deployed application with real authentication, logging, and monitoring
- One retrieval or search workflow that handles messy source content
- One evaluation story that explains how quality was measured and improved
- One trade-off writeup that compares model options, latency constraints, or data privacy decisions
A strong portfolio doesn’t need to be flashy. It needs to prove that the candidate can ship, observe, and improve.
Employers rarely struggle to find people who can call a model API. They struggle to find people who can own the consequences.
Candidates should also learn how to describe their work in business terms. “Built a RAG app” is vague. “Built an internal document assistant with access controls, trace logging, and fallback behavior” is much stronger because it signals production awareness.
How Nexus IT Group Bridges the AI Talent Gap
AI hiring is difficult for a simple reason. The role keeps changing while employers still need people who can deliver under current constraints.
Some teams need engineers who can integrate foundation models into existing products. Others need platform-minded builders who can design data flows, deployment patterns, evaluation loops, and governance controls from the start. A generic recruiting process often misses that distinction, which is why companies end up interviewing the wrong mix of researchers, backend engineers, and ML specialists.
For employers, a specialized recruiting partner can help translate business needs into the actual capabilities required for the role. That includes clarifying whether the opening is really AI engineering, ML engineering, platform engineering, or a hybrid position with narrow ownership. One relevant option for companies building this function is AI engineer recruiters and staffing support, which focuses on hiring for AI and ML-oriented roles.
For candidates, the same gap shows up from the other side. Many qualified engineers undersell themselves because their titles don’t match their real work. A backend engineer who has shipped LLM-powered workflows, built monitoring around inference calls, and managed production integrations may be closer to an AI engineer than the resume headline suggests.
The practical takeaway is simple. AI engineering is no longer a niche title reserved for a small research-heavy group. It’s an operating role, and hiring for it works best when the company defines the system, the risks, and the business outcome before the search begins.
Teams that need AI engineers usually don’t need more buzzwords. They need a hiring partner that understands how software, cloud, ML, and production operations come together in one role. nexus IT group supports employers hiring for specialized technology positions and helps candidates explore opportunities where their real skills match the work that needs to get done.