
The market for AI talent changed faster than most hiring teams changed their process. Demand for generative AI skills moved from 55 unique job postings in January 2021 to nearly 10,000 by May 2025, according to Lightcast’s generative AI labor market analysis. That’s the backdrop for any company trying to hire AI engineers in 2026.
Most hiring misses don’t start with weak sourcing. They start with a bad definition of the role. Companies write “AI engineer,” interview for general software ability, and then expect the person to research models, productionize systems, talk to stakeholders, and somehow clean up the data layer too. That approach burns time, loses strong candidates, and usually produces a mismatch even when someone accepts.
A stronger playbook starts with precision. Define the business problem. Translate it into the capabilities required. Build an interview loop around real work. Then make an offer that reflects how scarce the market is and onboard in a way that sets the hire up to ship.
Table of Contents
- Defining the AI Role Your Business Actually Needs
- Actionable Sourcing Strategies for AI Talent
- Screening and Assessments That Predict Performance
- The High-Impact AI Engineer Interview Framework
- Crafting Competitive Offers and Closing Candidates
- Effective Onboarding and Retention for AI Engineers
Defining the AI Role Your Business Actually Needs
The first hiring decision isn’t who to target. It’s what kind of AI hire the company needs. That sounds obvious, but it’s where many searches derail.
Employers are dealing with a genuine classification problem, not just a sourcing problem. The World Economic Forum’s 2025 Future of Jobs report identifies AI and machine learning specialists as fast-growing roles while employers also report persistent skills gaps as a barrier to transformation, as summarized in this hiring analysis from DistantJob. In practice, that means the hard part isn’t only finding talent. It’s separating adjacent profiles before the search starts.
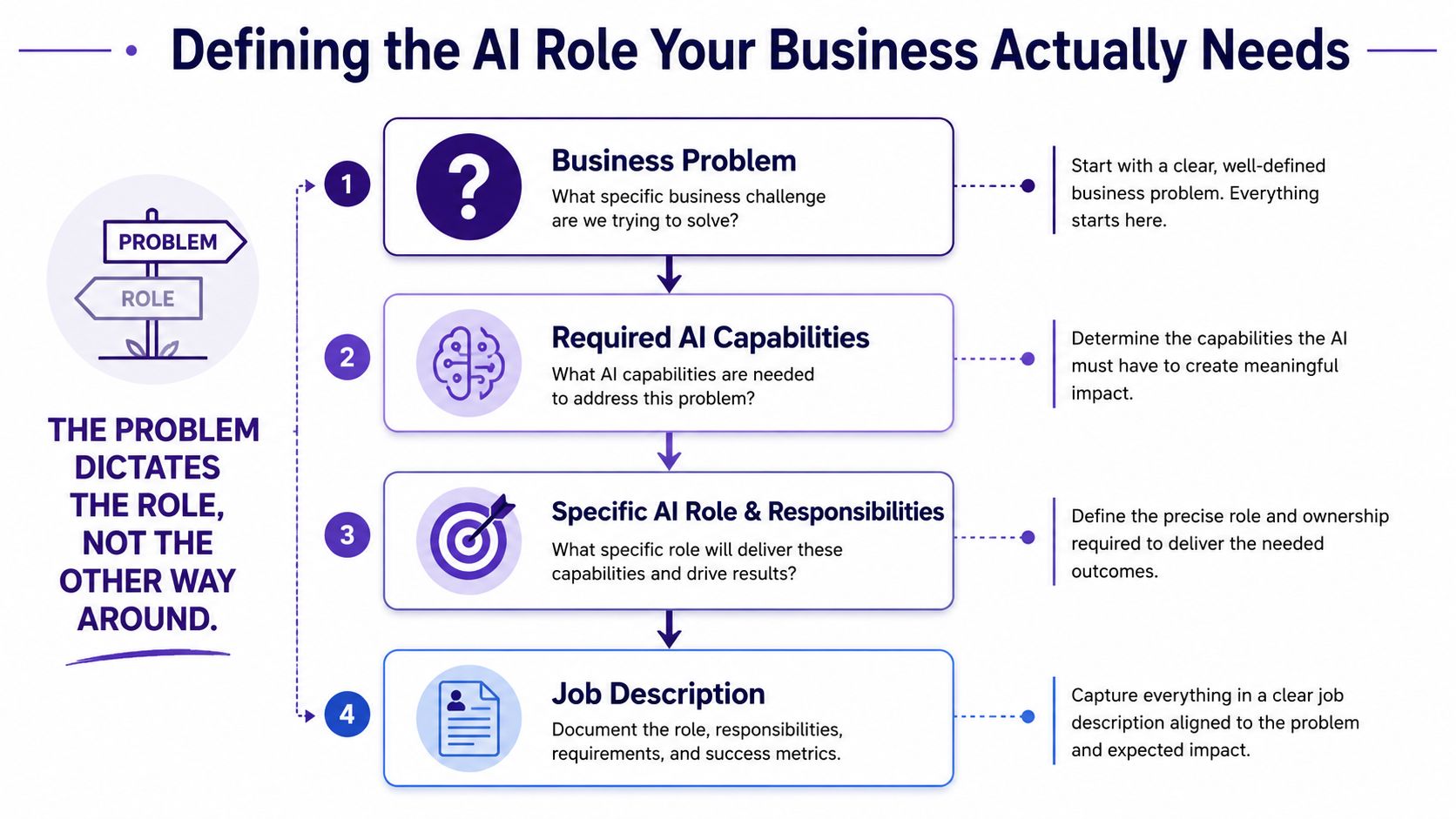
Start with the business problem, not the title
A title like “AI engineer” often hides three very different jobs:
- Research scientist work involves model experimentation, novel methods, and deeper theoretical depth.
- ML engineering work centers on training pipelines, deployment, monitoring, reliability, and infrastructure.
- Applied AI engineering work usually means integrating models into products, building LLM features, designing RAG workflows, and shipping dependable user-facing systems.
That distinction matters because hiring for the wrong profile creates predictable failure modes. A research-heavy candidate may be excellent at experimentation but frustrated by API orchestration, service reliability, and delivery pressure. A strong backend engineer with LLM fluency may ship customer value quickly, but won’t be the right choice if the mandate is frontier model research.
Practical rule: If the business needs a feature in production, the company usually needs applied engineering depth before it needs research prestige.
Useful role definition starts with a short set of questions:
- What business problem needs to be solved? For example, document search, workflow automation, forecasting, or internal copilots.
- What kind of system must be built? Prototype, production API, training pipeline, evaluation harness, or data platform.
- What constraints matter most? Latency, cost, observability, compliance, maintainability, or model quality.
- Who will this person work with? Product, infrastructure, analytics, legal, or research teams.
Teams that want a clean framework for that exercise can borrow from Ekipa AI’s strategic insights, which are useful for connecting AI initiatives to operating priorities before the requisition is opened.
AI role profile comparison
| Role Profile | Primary Focus | Key Skills | Sample Interview Question |
|---|---|---|---|
| Applied AI Engineer | Shipping AI-powered product features | LLM integration, RAG design, backend systems, evaluation, observability | How would this candidate design a customer-facing assistant that can fail safely when retrieval quality drops? |
| ML Engineer | Production ML systems and lifecycle management | Model deployment, feature pipelines, monitoring, MLOps, distributed systems | How would this candidate move a model from experimentation into a monitored production service? |
| AI Researcher | Advancing model capability or solving novel modeling problems | Deep learning, experimentation, model architecture, evaluation methodology | When would this candidate reject a promising model result because the evaluation setup is misleading? |
| Data Engineer with AI adjacency | Building the data layer that AI systems depend on | ETL, data quality, storage, orchestration, governance | How would this candidate design a pipeline that keeps training and inference data consistent over time? |
Turn role clarity into a usable job description
Once the role is defined, the job description should reflect workstreams, not a catch-all fantasy profile. Recruiting guidance from Acceler8 Talent recommends breaking AI hiring into distinct categories such as research, analytics, MLOps, and production engineering, because vague descriptions increase candidate drop-off and confuse evaluation later in the process. Their guidance also notes that specialist recruiters can reduce time-to-hire by up to 30% when the process is focused and aligned to the actual work, as detailed in their 2025 machine learning hiring guidance.
A good JD should define:
- Business context instead of generic AI ambition
- Core responsibilities tied to one role profile
- Stack expectations that reflect current systems, not aspirational future tooling
- Success criteria for the first months on the job
- Decision rights around architecture, model selection, and deployment
For teams that want a starting point, this AI engineer job description template is useful as a baseline, but it works best when the responsibilities are narrowed to the exact profile being hired.
Actionable Sourcing Strategies for AI Talent
More than half of AI job postings now sit outside traditional IT and computer science functions, as noted earlier in this guide. That matters because your competition is no longer limited to AI labs and software companies. Product teams, operations groups, healthcare providers, financial firms, and support organizations are all trying to hire from the same pool.
That pressure changes how sourcing should work.
A company hiring an AI Researcher should source in different places, and with a different message, than a company hiring an Applied AI Engineer to ship retrieval, inference, and evaluation workflows into production. This is the first sourcing mistake I see. Teams define the role loosely, then build a sourcing plan that treats researchers, ML engineers, and applied builders as interchangeable.

Where qualified AI candidates show up
Strong AI candidates are easier to find where they publish, contribute, and discuss technical work. They are harder to find in broad applicant pools, especially for roles that require production judgment.
Three channels usually produce the best signal:
- Open-source ecosystems. GitHub activity around model serving, evaluation frameworks, vector infrastructure, agent tooling, orchestration layers, and MLOps pipelines often reveals engineers who have touched real systems instead of course projects.
- Technical communities. Hugging Face, Kaggle, selected Slack and Discord groups, local ML meetups, and specialized forums can surface people who are experimenting with current tools and sharing implementation details.
- Conference and research-adjacent networks. These channels matter more for AI Researchers and some senior ML roles than for applied product hires. A poster session, paper list, or workshop speaker roster can be a strong sourcing map when the role depends on model innovation or deep specialization.
Good sourcing starts before outreach. Editorial roundups like this guide to essential AI startup news can help recruiters track which tools, teams, and startup clusters are attracting the kind of engineers they want to hire.
Match the channel to the role type
The sourcing channel should reflect the work.
If the role is AI Researcher, target research communities, publication trails, conference networks, and labs. If the role is ML Engineer, look harder at candidates who have built training pipelines, deployment systems, feature stores, and model monitoring. If the role is Applied AI Engineer, prioritize engineers with evidence of shipping copilots, search systems, recommendation workflows, LLM-backed features, or internal AI products tied to user outcomes.
That distinction saves time. It also improves response rates, because outreach lands better when the message reflects the work the candidate already does.
Comparing sourcing channels
A blended sourcing model usually outperforms a single-channel approach, but each option has a clear trade-off.
| Sourcing Channel | Best Use Case | Trade-off |
|---|---|---|
| Specialist recruiters | Hard-to-fill roles, confidential searches, fast-moving searches | Higher cost, but stronger calibration and access to passive talent |
| In-house direct sourcing | Repeatable hiring at scale, employer brand strength | Requires recruiter fluency in AI role distinctions and a disciplined outbound process |
| Technical communities | Relationship-building and niche discovery | Slower, less predictable, depends on credibility and consistency |
| Employee referrals | High-trust leads | Limited reach if the current team is narrow or homogeneous |
The decision is not recruiter versus no recruiter. It is whether your team can identify the right profile before outreach starts. Companies building a repeatable outbound engine can use frameworks from this guide on sourcing for recruitment to structure market maps, role segmentation, and contact sequencing.
Full-time versus contract for AI work
This choice should follow the scope of work, not the hype around AI.
Full-time hires fit best when the role owns product IP, model quality standards, platform decisions, internal tooling, or long-term collaboration with product and infrastructure teams.
Contractors or consultants make sense for a bounded proof of concept, a short MLOps cleanup, vendor evaluation, or a specialized implementation on a narrow stack.
A simple filter works well:
- Choose full-time when system ownership, team context, and knowledge retention matter.
- Choose contract when the project is time-boxed, exploratory, or tied to a narrow technical problem.
- Choose hybrid when an internal lead should own the roadmap, but outside specialists can speed up the first phase.
Many hiring misses start in sourcing, not interviews. Teams use one playbook for every AI title, then wonder why the funnel fills with candidates who look strong on paper but do not match the work.
Screening and Assessments That Predict Performance
Teams miss on AI hiring during screening more often than they miss in final interviews. The pattern is consistent. Companies screen for familiarity with tools, then hire into work that depends on judgment, shipping discipline, and role fit.
That mismatch gets expensive fast, especially if the company never clarified whether it needed an AI Researcher, an ML Engineer, or an Applied AI Engineer in the first place. A researcher may be excellent at experimentation and model discovery, but weak for a role centered on service reliability and deployment. An ML Engineer may be strong on infrastructure and monitoring, but the wrong choice for a product team that needs someone to shape user-facing AI behavior. Screening should test the work tied to the role definition, not generic AI fluency.
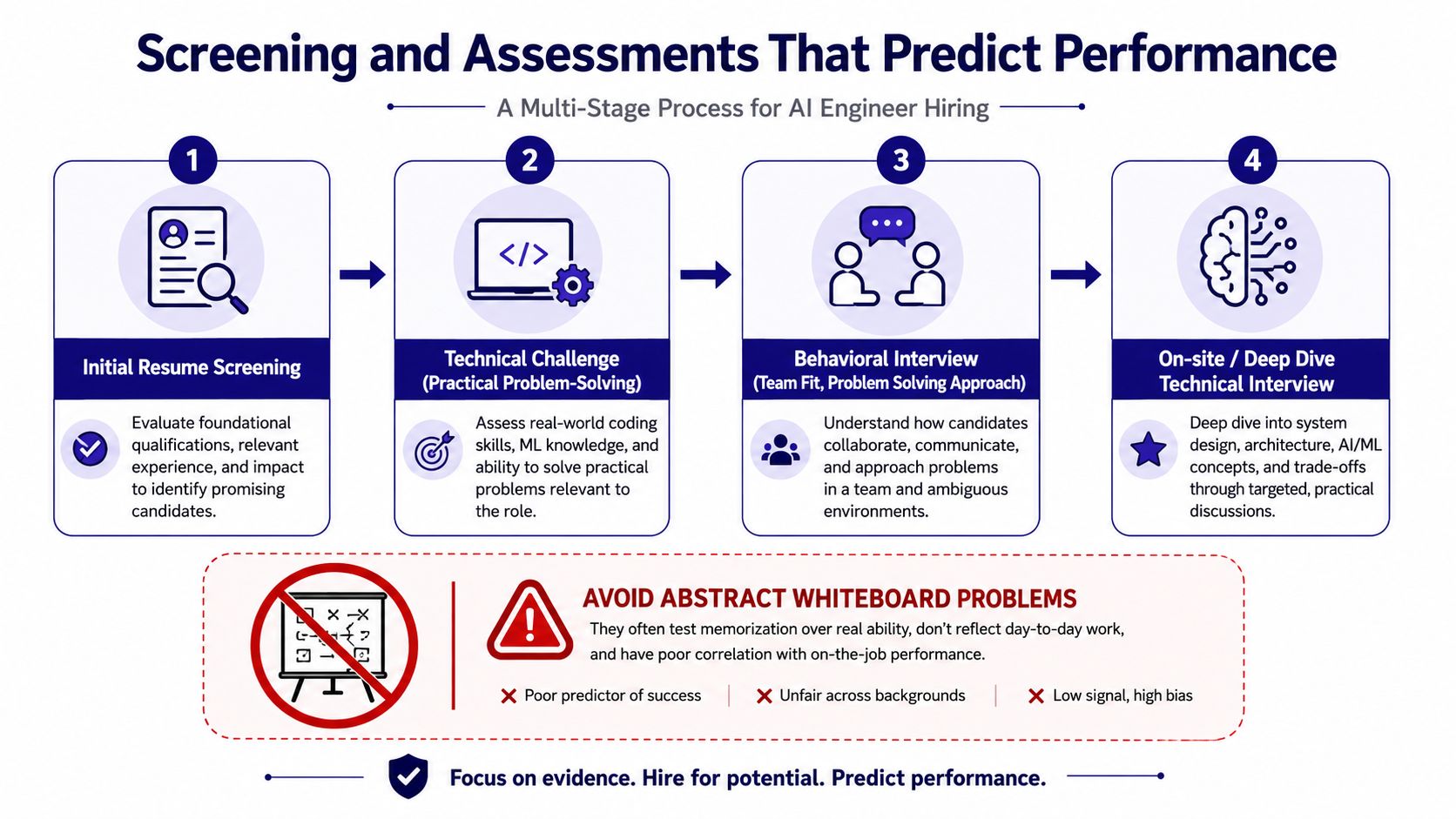
Screen for applied evidence, not buzzwords
Resume review works best as a calibration step, not a decision point. The question is simple: has this person done work close enough to your environment that an interview is worth the time?
For Applied AI Engineers, the strongest resumes usually show shipped product features, evaluation methods, prompt or retrieval decisions, and collaboration with product and design. For ML Engineers, I look for model serving, data pipelines, observability, CI/CD, rollback planning, and ownership of production systems. For AI Researchers, the signal shifts toward experimental design, publication or open-source depth, and evidence that they can turn research into a usable path for the business.
Signals that carry weight:
- Owned delivery: APIs, copilots, recommendation systems, search, internal automation, or model-backed user features
- Operational judgment: logging, monitoring, testing, incident response, fallback logic, and service ownership
- Data realism: messy source data, drift, retrieval failure modes, weak labels, missing values, and evaluation gaps
- Cross-functional range: business trade-offs, stakeholder communication, and decisions made under product constraints
Signals that are often overrated:
- long lists of libraries with no evidence of ownership
- generic “AI enthusiast” language
- puzzle-style coding strength used as a stand-in for production skill
- academic depth that does not map to the role
A resume should answer one practical question. What has this candidate been trusted to own?
Design a take-home that mirrors production work
The best assessment is short, role-specific, and close to the work your team needs done. Acceler8 Talent recommends a 3-hour take-home project built around a real production problem in their hiring guidance for machine learning roles. That benchmark is useful because it tests relevant skill without asking candidates to donate a weekend.
The format should change by role.
An Applied AI Engineer can be asked to improve a small RAG workflow, define evaluation criteria for response quality, or design fallback behavior for a model-backed feature. An ML Engineer can be asked to work through an inference optimization task, model serving design, or monitoring plan for a degraded endpoint. An AI Researcher is better assessed through experiment design, evaluation rigor, ablation logic, or a structured review of modeling choices.
Good take-home options include:
- A scoped RAG task with chunking, retrieval, and answer validation choices
- An inference optimization exercise where latency, throughput, and cost all matter
- A model serving prompt covering API design, fallback handling, and observability
- An evaluation challenge where the candidate must define what to measure and defend the metric choices
Hiring advice: If the assignment doesn’t resemble work the team does, it won’t predict on-the-job performance.
Scoring should stay disciplined. Use a rubric that covers:
- quality of technical choices
- clarity of assumptions
- handling of edge cases
- explanation of trade-offs
- maintainability of the solution
- awareness of operational risk
The debrief matters as much as the artifact. Strong candidates can explain why they chose a simpler system, where they would add instrumentation, and what they would postpone in a first release. Weak candidates often present polished output but cannot defend the decisions behind it.
Keep the process tight and candidate-friendly
Process design affects hiring outcomes as much as test design. The same guidance also recommends a 48-hour post-interview decision window for hard-to-fill machine learning roles. That aligns with what many recruiting teams see in practice. Strong AI candidates leave slow funnels early, especially when they are balancing multiple processes.
A clean sequence is usually enough:
- Resume screen tied to the target role
- Short technical screen to verify depth and communication
- Practical take-home or live applied exercise
- Debrief conversation focused on decisions and trade-offs
- Fast final decision
Whiteboard-heavy loops are a poor fit for many AI roles. They favor recall and performance under artificial pressure, while missing the skills that decide whether an AI system works in production: role fit, judgment, evaluation discipline, and the ability to work through ambiguity with other teams.
The High-Impact AI Engineer Interview Framework
The interview loop should answer one question that the take-home can’t fully settle: Can this person make good decisions under ambiguity with other people involved?
That’s where many AI projects succeed or fail. RAND Corporation’s research, cited in Svitla’s analysis of common AI and ML pitfalls, identifies misunderstanding the problem to be solved as a leading cause of failure. Hiring should account for that directly. Candidates need to show they can translate business goals into model objectives and choose KPIs tied to real-world outcomes, not only technical metrics.
A four-part interview loop that surfaces judgment
A useful interview framework separates technical depth from systems thinking and communication.
Part one is the technical calibration screen. This should validate whether the person really matches the target role. For an applied AI engineer, ask about a shipped feature. For an ML engineer, ask about deployment, monitoring, and failure handling. For a researcher, ask about experimentation design and evaluation integrity.
Part two is the project deep dive. The candidate walks through one piece of work in detail. The interviewer should press on what changed because of the candidate’s decisions, what constraints existed, what went wrong, and what trade-offs were accepted.
Part three is the model or system design conversation. In this conversation, a hiring team learns whether the candidate can build from a messy prompt. Good prompts are business-shaped, not purely technical. “Design an internal support assistant with audit requirements” is better than “design a chatbot.”
Part four is the behavioral and collaboration interview. AI engineers need to explain uncertainty, limits, data issues, and deployment risk to non-specialists. A candidate who can’t do that often creates friction even with strong raw skills.
The strongest interview loops test whether a candidate can connect product intent, model behavior, and operational reality in one conversation.
Questions that test framing, trade-offs, and communication
Questions improve when they force the candidate to make choices.
A few examples:
- A product leader wants an AI feature in one quarter. How would the candidate narrow scope for the first release?
- The model looks strong offline, but user trust is weak after launch. What would the candidate investigate first?
- A stakeholder asks for a custom model. When would the candidate push for an API-based or retrieval-based approach instead?
- The data has gaps, duplicated records, or bias concerns. How would the candidate decide whether the project is ready to move forward?
- Which KPI would the candidate prioritize if accuracy, cost, and latency pull in different directions?
Behavioral questions should be equally concrete:
- Tell the candidate to describe a time an experiment failed and what changed afterward.
- Ask how they explain model limitations to a non-technical executive.
- Ask where they draw the line between “good enough to launch” and “not safe enough to ship.”
A weak interview loop hunts for trivia. A useful one reveals how the candidate frames problems, communicates constraints, and behaves when the answer isn’t obvious.
Crafting Competitive Offers and Closing Candidates
A 2026 market review estimated the average AI engineer salary in the U.S. at about $206,000, up from roughly $155,000 the prior year, and cited 23% projected growth from 2023 to 2033 for computer and information research scientists, a category that overlaps with AI engineering work, according to 365 Data Science’s AI engineer salary and outlook review. Hiring teams should plan for a market that stays tight, especially for candidates who can ship production systems, not just prototype models.
That pressure gets worse when the role definition is fuzzy.
A company hiring an AI Researcher, an ML Engineer, and an Applied AI Engineer should not use one compensation template for all three. These candidates are priced differently because the work, scarcity, and expected impact differ. If the offer does not match the role, strong candidates read it as a sign that the company still has not decided what it needs.
Why compensation strategy has to be deliberate
The same analysis found that 34% of reviewed AI roles advertised salaries between $160,000 and $200,000, 18% offered $120,000 to $160,000, and 13% paid above $200,000 across a sample of 1,000 job postings. That does not mean every company needs to pay at the top of the band. It does mean the range has to make sense for the hiring brief, the market, and the difficulty of the problems the person will own.
Comp strategy should reflect the role profile:
- AI Researchers often weigh publication latitude, research time, quality of peers, and access to serious compute.
- ML Engineers tend to look closely at platform maturity, model deployment patterns, monitoring expectations, and how much infrastructure debt they are inheriting.
- Applied AI Engineers usually care most about product scope, speed to production, cross-functional support, and whether the company can turn experiments into shipped features.
Before locking the range, hiring teams should benchmark against current AI engineer salary data in the U.S. and then adjust for the exact role they are trying to fill.
What strong AI candidates evaluate beyond salary
Compensation gets a candidate to stay in the process. It rarely closes them on its own.
Strong candidates assess whether the company can support the kind of work it says it wants done. I have seen candidates walk away from strong cash offers because they discovered there was no usable data pipeline, no clear product owner, or no budget for inference at production volume. Those are not secondary details in AI hiring. They define whether the role is attractive.
Candidates usually evaluate four things:
- Problem quality. The work should tie to a real business problem, not a vague mandate to “add AI.”
- Execution environment. Data access, tooling, deployment paths, and stakeholder support need to be in place or at least funded and planned.
- Decision speed. Good candidates lose interest when every model, vendor, and release decision sits in a long approval chain.
- Career path. They want to know whether the role leads to deeper technical ownership, architecture work, people leadership, or a recognized specialty.
A strong offer makes those points concrete. It explains the mission, who owns what, what the first 12 months should produce, and what constraints are already known.
How to close without creating friction
Closing starts well before the offer call. Recruiters and hiring managers should know, before final interviews wrap, whether the candidate is optimizing for cash, title, remote flexibility, research freedom, product ownership, or team quality. That information shapes the offer and the conversation around it.
The mechanics matter:
- Align on range and scope early so late-stage surprises do not kill momentum.
- Present the full package including salary, equity if relevant, reporting line, ownership boundaries, and expected first-year outcomes.
- Move fast after final interviews because delays signal indecision or internal misalignment.
- Negotiate directly and state what is flexible, what is fixed, and why.
The closing mistake I see most often is simple. The company makes an offer before proving it understands why this specific AI hire matters. In a crowded market, the candidates who can choose among offers notice that immediately.
Effective Onboarding and Retention for AI Engineers
A signed offer doesn’t validate the hire. The first months do.
AI engineers ramp slowly when access is fragmented, goals are vague, and no one has defined what “good” looks like in the environment they just joined. That’s especially costly in AI work because progress depends on data access, tooling, stakeholders, and infrastructure all lining up early.
A practical 30-60-90 day onboarding plan
A strong onboarding plan gives the new hire enough structure to move fast without forcing a fake sprint.
First 30 days
The immediate priority is environment access and context. The engineer should get development tooling, model or API credentials, data permissions, documentation, architecture diagrams, and introductions to the key product, data, and platform stakeholders. This is also the right window to review prior experiments, failed approaches, and current constraints.
Useful outcomes for this phase include:
- a clear understanding of the business problem
- visibility into the current stack and data quality realities
- agreement on what the first meaningful deliverable should be
Days 31 to 60
The engineer should start owning a bounded project with a realistic path to an early win. Good first projects are specific enough to finish and important enough to matter. That could be improving an evaluation workflow, tightening a retrieval pipeline, instrumenting a weak inference path, or shipping a small internal AI feature.
During this phase, managers should watch for:
- how the person asks clarifying questions
- whether they escalate blockers early
- how they reason about trade-offs with product and infrastructure peers
Days 61 to 90
By this point, the engineer should be operating with more independence. The focus shifts from setup to contribution quality. The person should be able to explain risks, propose priorities, and make technical recommendations grounded in business reality.
A useful checkpoint at this stage includes:
- what the engineer shipped or materially improved
- what they learned about the system’s bottlenecks
- what support or structural changes would raise output in the next quarter
Retention depends on design, not perks alone
Retention for AI talent usually breaks for the same reasons hiring does. Poor role definition, weak problem framing, scattered ownership, and unrealistic expectations push people out quickly.
The environments that retain AI engineers tend to share a few traits:
- Clear career paths. Senior ICs need room to grow without being forced into management.
- Protected learning time. The field changes quickly, and people notice when there’s no space to keep up.
- Healthy experimentation norms. Teams need room to test ideas without treating every failed trial as waste.
- Cross-functional credibility. AI engineers stay longer when product and leadership understand the limits and realities of the work.
The best retention tactic is simple. Give the engineer a real problem, the authority to solve it, and an environment that doesn’t fight the work every day.
Companies that need to hire AI engineers often lose time at the exact points where specialization matters most: role definition, sourcing calibration, interview design, and closing speed. nexus IT group is one option for employers that need support on hard-to-fill technology searches, including AI engineering roles, when internal hiring teams need added market coverage or specialized recruiting help.